
ガイドブック
Data Fusion Services(DFS)の紹介
はじめに
Data Fusion Services(DFS) は、DataMesh FactVerse デジタルツインクラウドプラットフォームに付随するデータ融合サービスです。
DFS の目的は、企業の業務システムに存在する 構造化データと非構造化データ を正確かつ効率的にデジタルツインモデルへ接続し、データ駆動型のデジタル世界 を実現することにあります。
DFS を利用することで、現場で収集されたリアルタイムデータをプラットフォームに接続し、処理後に XR クライアント、可視化ダッシュボード、AI 推論エンジンなどの各種エンドポイントに出力できます。これにより、「業務システム – デジタルモデル – アプリケーション連携」 のデータサイクルを構築できます。
DFS の代表的な価値:
- 現実とツインをつなぐ:実際の設備、生産ライン、または現場の業務データを FactVerse デジタルツインにマッピング。
- データ資産の蓄積を促進:分析手法や業務ノウハウを共有・再利用可能なインテリジェント資産へ変換。
- データ駆動型意思決定を加速:データ成果を可視化し、多端末でのインタラクティブな操作や業務モニタリングを支援。
コアデータリンクアーキテクチャ
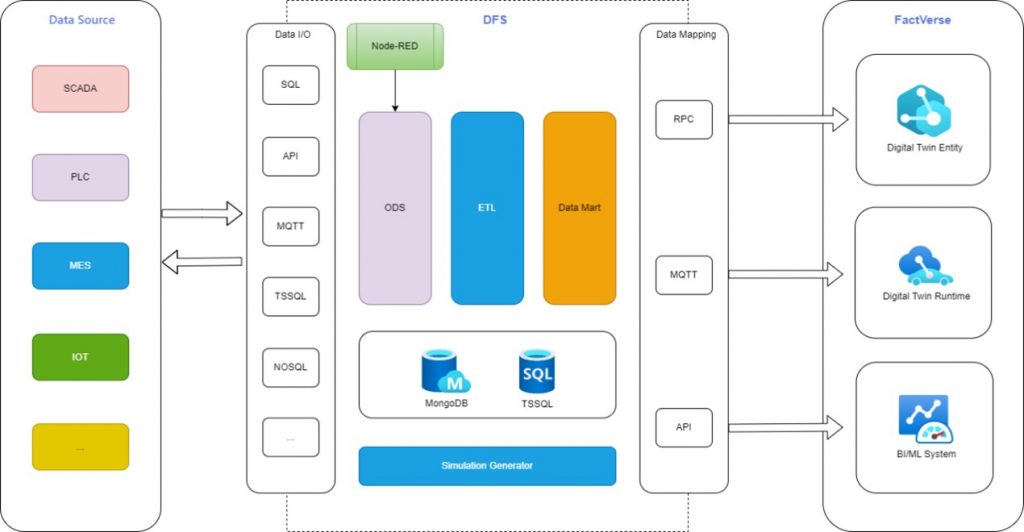
DFS は以下の 3 つのコアプロセスで構成されています:
フェーズ | 機能説明 |
データ入力と保存 | 企業の業務システムやデータ収集プラットフォームと接続し、構造化データを DFS に取り込み、統合的に保存・管理(バックアップを含む)。 |
データ加工と処理 | 事前定義されたルールやカスタムメソッドに基づき、データのクレンジング、変換、分析処理を行い、その後のモデリングや表示に備える。 |
データ構成と出力 | アプリケーション要件に応じてデータパネル、グラフ、XR 表示形式を生成し、FactVerse プラットフォームに出力してデジタルツインの可視化やインタラクションを支援する。 |
システムログイン
- ブラウザを開き、URL を入力してログイン画面にアクセスします。
 をクリックすると、ページ言語を切り替えることができます。DFS は 簡体字中国語・英語・日本語・繁体字中国語 の 4 種の表示言語に対応しています
をクリックすると、ページ言語を切り替えることができます。DFS は 簡体字中国語・英語・日本語・繁体字中国語 の 4 種の表示言語に対応しています をクリックすると、接続先サーバーを切り替えることができます
をクリックすると、接続先サーバーを切り替えることができます- アカウントとパスワードを入力します(企業管理者にお問い合わせください)。
- 【ログイン】をクリックします。