
ガイドブック
機能説明
シミュレーションタスク管理
シミュレーションタスク管理モジュールは、履歴データまたはシミュレーションデータに基づいて実行されるシミュレーションタスクの管理と設定を行うための機能です。
履歴データソースシミュレーションタスクの作成
履歴データソースシミュレーションタスクは、データのリプレイ、シミュレーションテスト、トレンド分析に利用でき、ユーザーが設備やシーンの履歴データに基づいてシミュレーションを実行するのに役立ちます。
履歴データの準備
履歴データの定義
履歴データとは、デジタルツインシーンや実際の設備が稼働中に継続的に記録した時系列データを指します。DFS はこれらのデータを自動的に保存・蓄積し、シミュレーションタスクに信頼できる入力を提供します。
履歴データの種類と入手元
種類 | 入手元 | 典型的な用途 | 例 |
シーン履歴データ | シーン実行またはリプレイ時に自動生成 | シーン全体のリプレイ、複数設備の相互分析 | 生産ラインシーン:ロボットアーム+コンベア+検査工程の協調動作 |
設備履歴データ | ・設備バインドページからインポート・アダプターインスタンス作成時に接続・シミュレーションタスク作成時にアップロード | 単一設備の状態検証、アルゴリズムテスト、特徴抽出 | NC工作機械 A の主軸回転数と温度記録 |
補足
- シーン履歴データを利用する場合:DFS 内で以下を事前に実施してください:
- 設備情報の作成(手順は「設備とツインモデルのバインド」を参照)。
- シーンのインポート。
- シーン内のツインモデルと設備のバインド。
- 設備履歴データを利用する場合:以下のいずれかの方法を選択可能です(詳細手順は「設備とツインモデルのバインド」を参照)。
- 設備バインドページからインポート
- アダプターインスタンス作成時に接続
- シミュレーションタスク作成時にアップロード
シミュレーションタスクの作成
前提条件
選択した設備またはシーンに履歴データが存在することを確認してください。データがない場合、シミュレーションタスクは正常に実行できません。
操作手順
- 新規タスク作成:[シミュレーションタスク管理 > 履歴データソースシミュレーション]ページで【新規タスク】をクリックし、新規作成ウィンドウを開きます。
- タスク名入力:タスク名を入力します。
- データ選択:設備またはシーンに基づくデータを選択します:
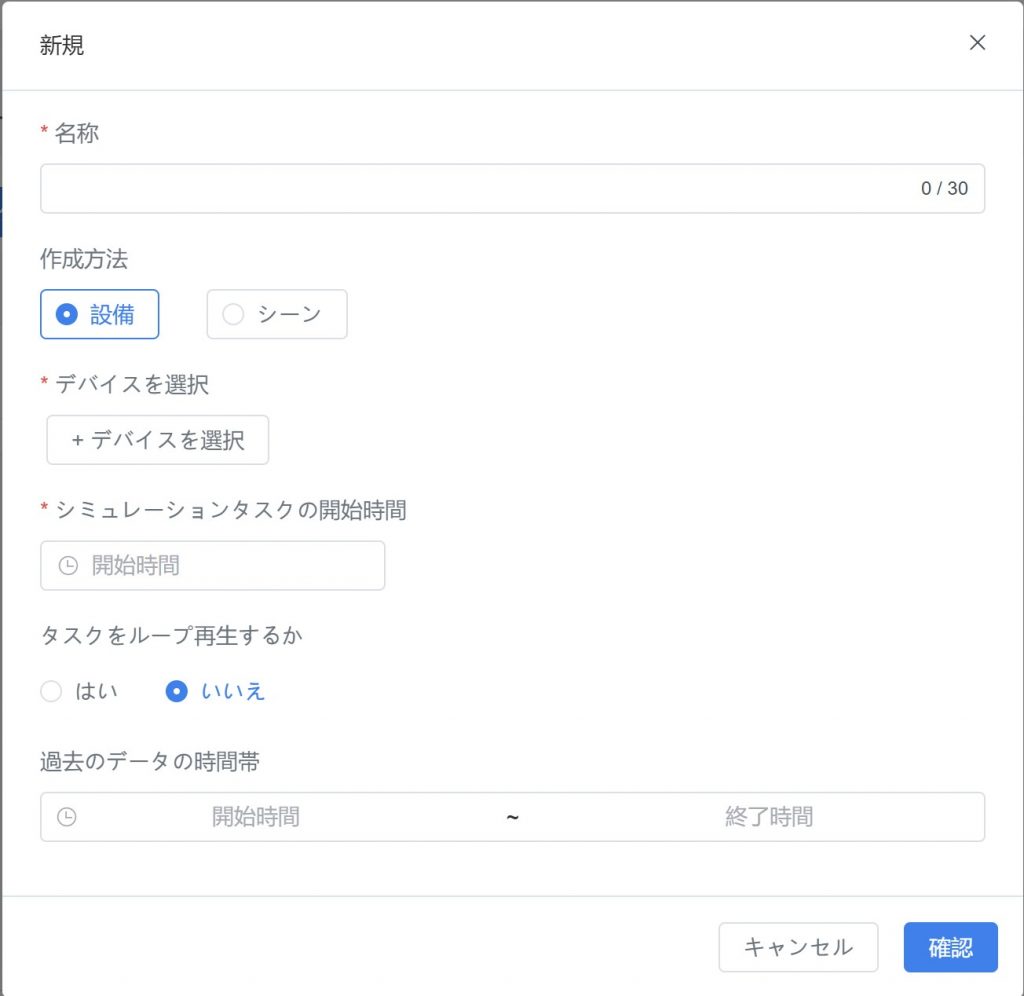
- 設備履歴データ:[設備]オプションを選択し、【+設備を選択】をクリックして設備一覧からシミュレーションに使用する設備を選択します(複数選択可能)。
- シーン履歴データ:[シーン]オプションを選択し、【+シーンを選択】をクリックしてシーン一覧からシミュレーションに使用するシーンを選択します。
- シミュレーションタスク開始時間の設定:タスクの開始実行時間を設定しま。
- ループシミュレーションの有無を選択:
- 有効:新規作成したシミュレーションタスクがループ実行され、継続的なテストや長期展示シーンに適用されます。
- 無効:シミュレーションタスクは 1 回のみ実行され、単回テストや検証シーンに適用されます。
- (オプション)履歴データ範囲の選択:リプレイする履歴データの時間範囲を選択します。
- 作成の確定:【確認】ボタンをクリックし、シミュレーションタスクの作成を完了します。
完了後に得られるもの
- 履歴データに基づく新しいシミュレーションタスク。
- タスク一覧からリプレイを確認・実行可能。
- ツインモデルまたはシーンを駆動し、設備の履歴過程を再現することで、検証・展示・分析に活用可能。
ュレーションデータソースシミュレーションタスクの作成
シミュレーションデータソースは、実際の設備データが存在しない場合に、データストリームを生成してテスト・検証・展示をサポートするために使用します。
現実の設備やリアルタイムデータが不足している場合でも、シミュレーションデータファイルをアップロードすることで、仮想設備の初期データセットを作成できます。これらのデータは、その後のタスク実行時に設備の履歴データとしてシステムに保存されます。
利用シーン
- 設備テスト:特定環境下での設備データをシミュレーションし、設備の応答検証や設定最適化に活用。
- データ展示や検証:履歴データやリアルタイムデータが不足している場合に、シミュレーションデータを通じてシーン展示や検証を実施。
- 初期開発段階:設備が一時的にリアルタイムデータを出力できない場合でも、シミュレーションデータで検証・デモが可能。
データファイルの準備
対応ファイル形式:XLS / XLSX / TXT / JSON
シミュレーションデータファイルの入手方法
以下の方法でシミュレーションデータファイルを準備できます:
- システム提供のテンプレート(推奨)
- [シミュレーションタスク管理] > [シミュレーションデータソース]ページで、【新規タスク】 > Excel または Text テンプレートをクリックし、公式で定義済みの Excel / Text テンプレートファイルを取得可能。
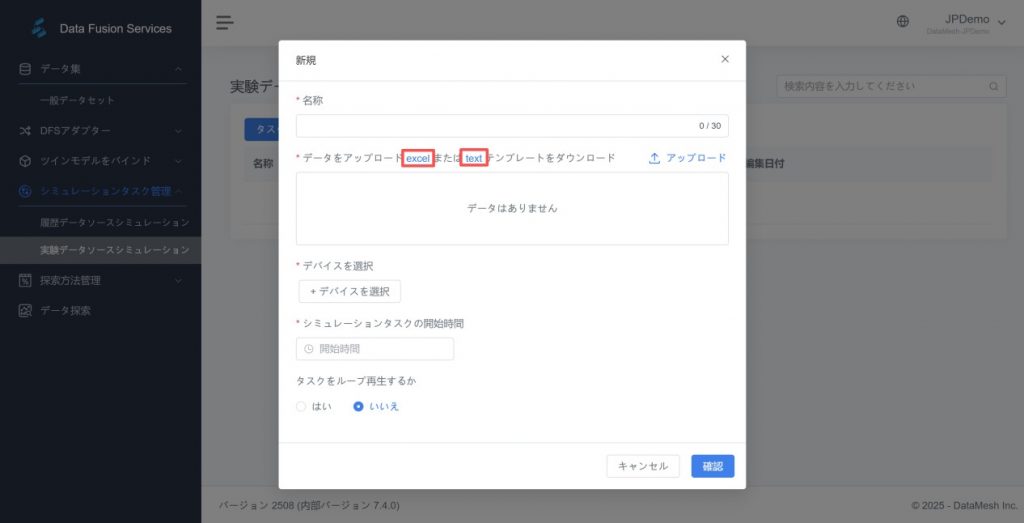
- テンプレートの要件に従って「設備名」「属性」「データ値」を入力し、そのままアップロードするだけで利用可能です。
- 設備システムからエクスポートされたデータを利用
- 既に PLC、MES、センサープラットフォームなどの設備システムがデータエクスポートをサポートしている場合、ユーザーは直接エクスポート可能です。
- エクスポートしたファイルは DFS のテンプレート形式に合わせて調整し、フィールド名、タイムスタンプ、属性名が一致するようにする必要があります。
- 手動構築またはシミュレーション生成データを利用
- 実設備が存在しない場合は、テンプレートに手動で入力(例:いくつかの主要属性にテスト値を設定)することができます。
- あるいは外部スクリプト/ツールを使用してテストデータを生成し、テンプレート形式に準拠したファイルに変換して利用できます。
Excel テンプレート例
設備名(name) | 設備属性(key) | 設備属性値(value) | データ生成タイムスタンプ(空欄可) |
TestDevice | temperature | 123 | 1709797575817 |
フィールド説明
- 設備名(name):設備の一意識別名。例:TestDevice
- 設備属性(key):属性名。例:温度、回転速度、圧力など。
- 設備属性値(value):属性に対応する数値。例:123
- データ生成タイムスタンプ:ミリ秒単位のタイムスタンプ。空欄可。空欄の場合、システムがアップロード時刻を自動補完します
Text/JSON テンプレート例
[ { “serial”: “Device name”, “ts”: “String or integer millisecond timestamp”, “datas”: { “key1”: “data1”, “key2”: “data2” } } ] |
パラメータ説明
- serial:設備名。
- ts:タイムスタンプ(ミリ秒)。
- datas:設備属性とその対応値。
- key:属性名
- data:属性値
⚠️ 注意:設備属性名はデジタルツインの属性名と一致している必要があります。不一致の場合は、「設備とツインモデルのバインド」手順で手動マッピングを行ってください。
シミュレーションタスクの作成
- 新規タスク作成:「シミュレーションタスク管理」>「シミュレーションデータソース」画面で【新規タスク】をクリックし、新規タスク作成ウィンドウを開きます。
- シミュレーションタスク情報の入力:
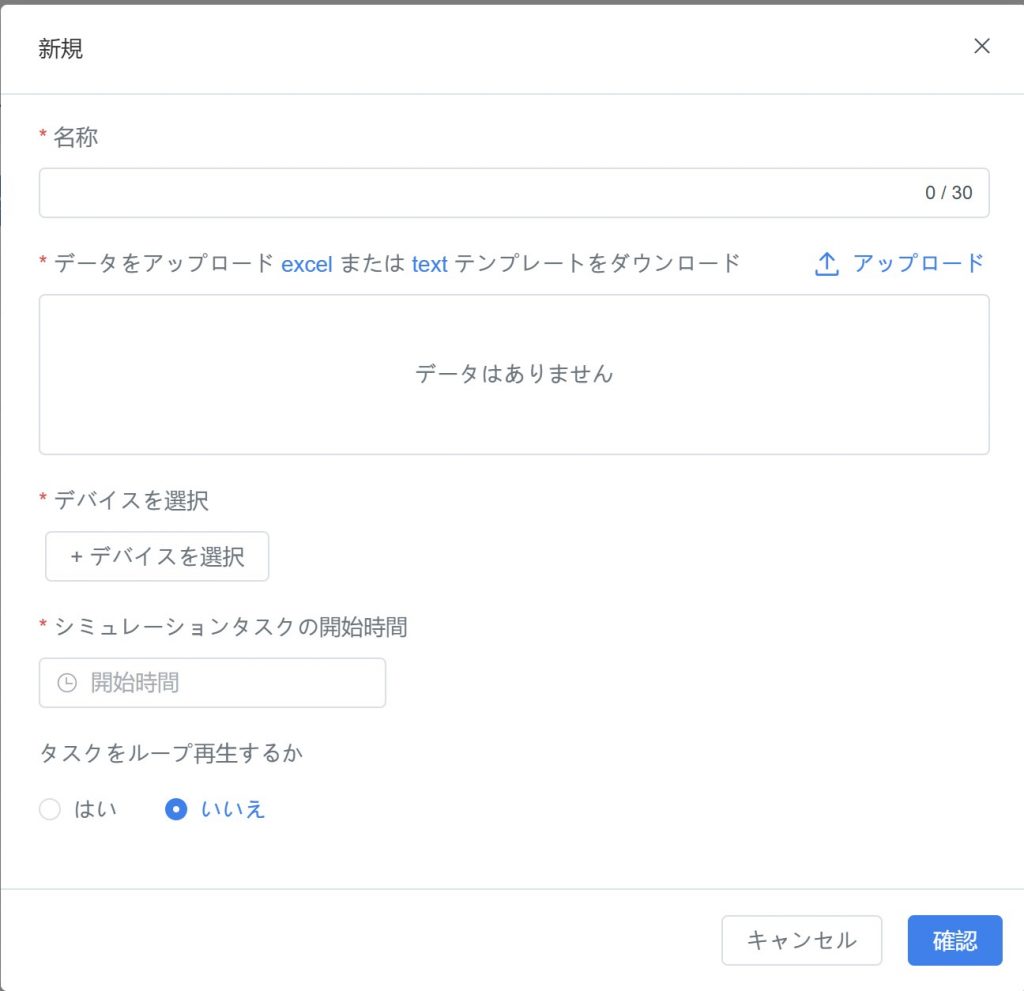
a) シミュレーションタスク名の入力:シミュレーションタスクの名称を入力します。
b) データのアップロード:設備データをインポートして設備情報を生成します。
- 既存のデータファイルをアップロード。
- またはシステム提供のテンプレートをダウンロードし、記入後に再アップロード(→「データファイルの準備」を参照)。
c) 設備の選択:【+設備を選択】をクリックし、設備リストからシミュレーションタスクに使用する設備を選択します。
注意:ここで選択する設備は、必ずアップロードしたデータファイルに含まれている必要があります。データファイルに含まれていない設備はシミュレーションタスクに参加できません。
d) シミュレーションタスク開始時刻の設定:シミュレーション開始時刻を設定し、シミュレーションデータ生成の時間範囲を決定します。
e) ループシミュレーションの有無を設定:
- 有効:新規作成したシミュレーションタスクは繰り返し実行され、継続的なテストや長期展示に適用されます。
- 無効:シミュレーションタスクは一度だけ実行され、単回テストや検証に適用されます。
- タスク作成の確認:【確認】ボタンをクリックして、シミュレーションタスクの作成を完了します。
完了後に得られるもの
- シミュレーションデータに基づく新しいシミュレーションタスク。
- このタスクは 再生可能なシミュレーションデータソース を生成し、ツインモデルの駆動、シーン展示、検証に利用可能です。
DFS アダプタ
DFS アダプタは外部データソースと DFS プラットフォームを接続するブリッジであり、主にリアルタイムデータの受信、前処理、変換を行い、DFS システム内で正しく解析・保存・活用できるようにします。
DFS アダプタを利用することで、設備・制御システム・業務プラットフォームのリアルタイムデータを FactVerse デジタルツインプラットフォーム に接続し、データ駆動のツインモデルのリアルタイム応答と業務連携を実現できます。
コア機能
- データ接入:PLC、IoT プラットフォーム、ゲートウェイなど各種産業データソースを接続。
- データ前処理:データのクリーニング、フォーマット変換、構造標準化。
- データ駆動のツインモデル:ツインモデル属性にバインドし、現場の稼働状態をリアルタイムに反映。
- 柔軟な設定:Node-RED によるグラフィカルフロー設定に対応、データ処理の透明性と効率を向上。
キー概念
名称 | 説明 |
アダプタテンプレート | 事前定義された Node-RED データフローテンプレート。データ収集、処理、クリーニングなどのルールを含み、迅速な再利用と標準化を可能にする。 |
アダプタインスタンス | テンプレートに基づいて作成される具体的なデータ接入ポイント。各インスタンスは一つの実際のデータソース接入タスクに対応し、独立したアドレス・ポート・キー等を設定。 |
リアルタイムデータソース | リアルタイムデータを出力する設備やプラットフォーム(PLC、センサーゲートウェイ、IoT プラットフォーム、産業プロトコルインターフェースなど)。 |
典型的なリアルタイムデータソースの利用シーン
シーンタイプ | 説明 |
動的モニタリング | 設備状態の変化(温度、回転数、位置など)をリアルタイムで収集し、ツインモデルの挙動に同期させる |
リアルタイム意思決定支援 | 最新データに基づき、生産ラインのスケジューリング、故障予測、エネルギー消費の最適化などの意思決定を行う |
データ処理・加工ルールの設定
アダプタインスタンスを本稼働させる前に、対応するデータ処理ロジックを設定する必要があります。これにより、収集したデータがシステムで正しく認識・クリーニング・保存されるようにします。
アダプタテンプレートの作成(任意)
アダプタテンプレートは処理フローを標準化するために使用され、複数のインスタンス間で再利用でき、重複した設定を削減することができます。テンプレートの内容は Node-RED フローの JSON ファイルです。
補足: 再利用の必要がない場合は、テンプレート作成を省略し、直接インスタンス内でフローを手動設定しても構いません。
操作手順
- 「DFSアダプタ > アダプタテンプレート」ページで【新規】をクリックします。
- テンプレート名を入力し、テンプレートデータ入力欄に Node-RED フローの JSON 形式を入力または貼り付けます。
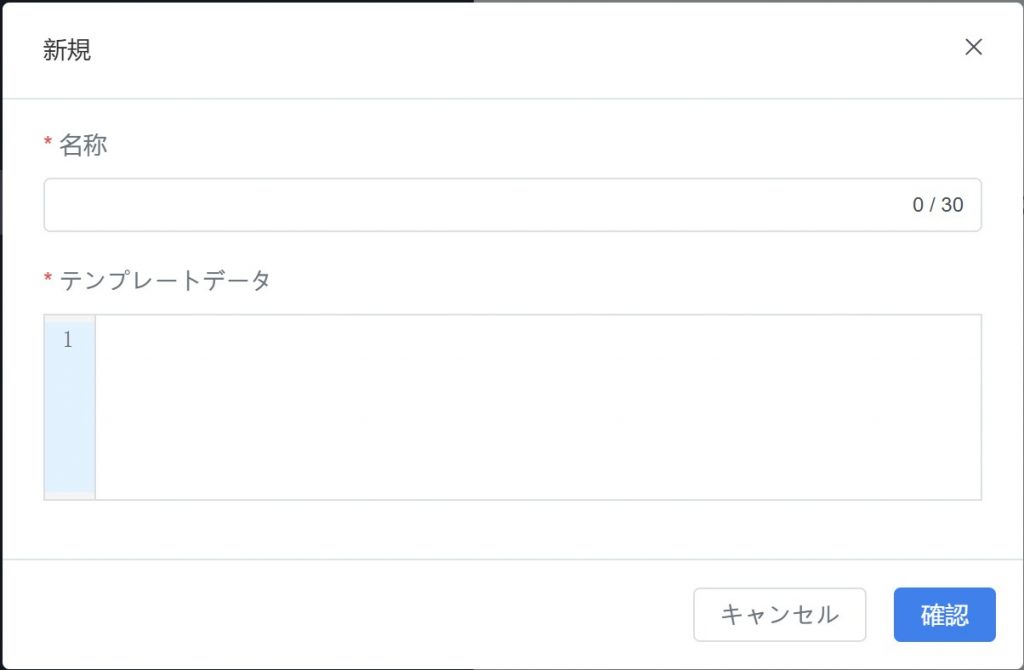
- 確認】をクリックしてテンプレートを保存します。
データ処理フローの編集(Node-RED)
Node-RED はグラフィカルなフローエディタであり、データの収集・解析・送信ロジックを可視化して設定するために使用されます。
操作手順
- ブラウザで対象アダプタインスタンスに対応する Node-RED アドレスへアクセスします。
- フロ―キャンバス上で以下の設定を行います:データ収集頻度、フィールド処理、出力フォーマット などのノードを構成。
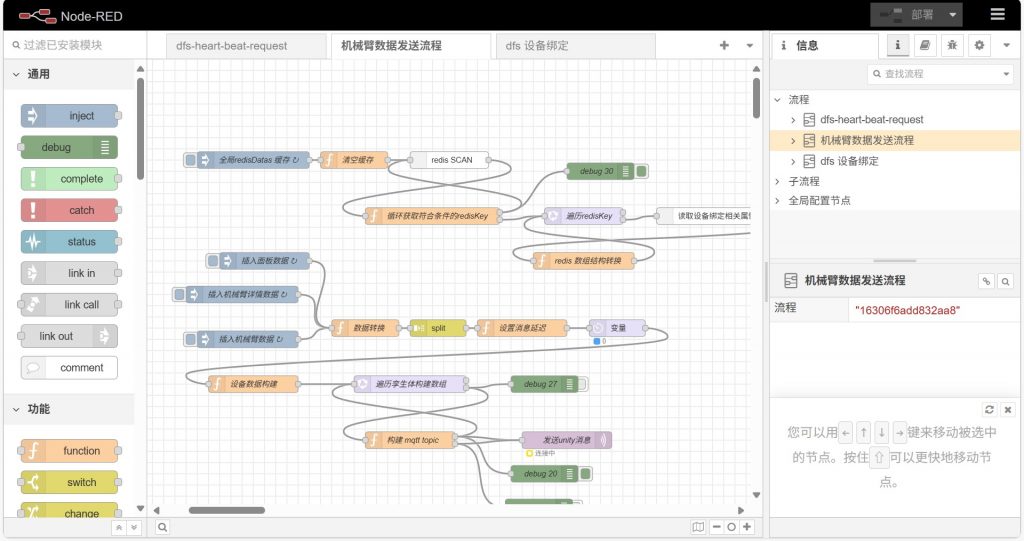
- 編集が完了したら【デプロイ】ボタンをクリックし、フローを実行中のアダプタサービスに適用します。
詳細な操作方法については《Node-RED ユーザーガイド》を参照してください。
アダプタインスタンスの作成
アダプタインスタンスは、具体的なデータソースと接続するための設定エントリです。各インスタンスは 1 つのデータ接入タスクに対応し、独立したリッスンアドレス、ポート、データ処理ロジックを持ちます。
インスタンスの作成
操作手順
- DFS アダプタ > アダプタインスタンス ページで【新規】ボタンをクリックし、新しいアダプタインスタンスを作成します。
- ポップアップウィンドウに以下の情報を入力します:
フィールド | 説明 |
名称 | 任意のアダプタインスタンス名。データソースを識別しやすくするため。 |
エッジキー(任意) | エッジデバイス認証をサポートし、データのセキュリティを強化。 |
IP | DFS アダプタサービスが管理する IP アドレス |
ポート | アダプタインスタンスのポート番号 |
説明(任意) | 当該アダプタインスタンスの簡単な説明 |
IP およびポート設定に関する補足:
- 単一マシンに複数のインスタンスをデプロイする場合:IP アドレスは同一、ポートは異なる。
- 複数マシンにデプロイする場合:実際のデバイス設定に基づき、インスタンスごとに異なる IP を使用。
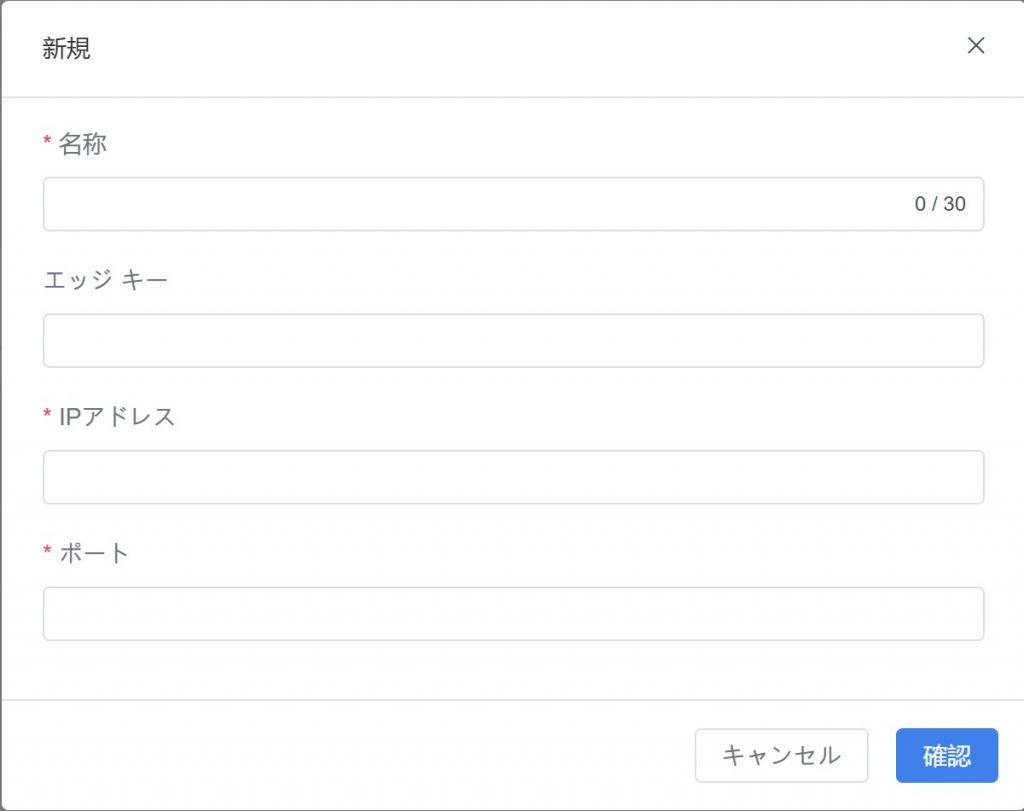
- 入力が完了したら【確認】をクリックします。
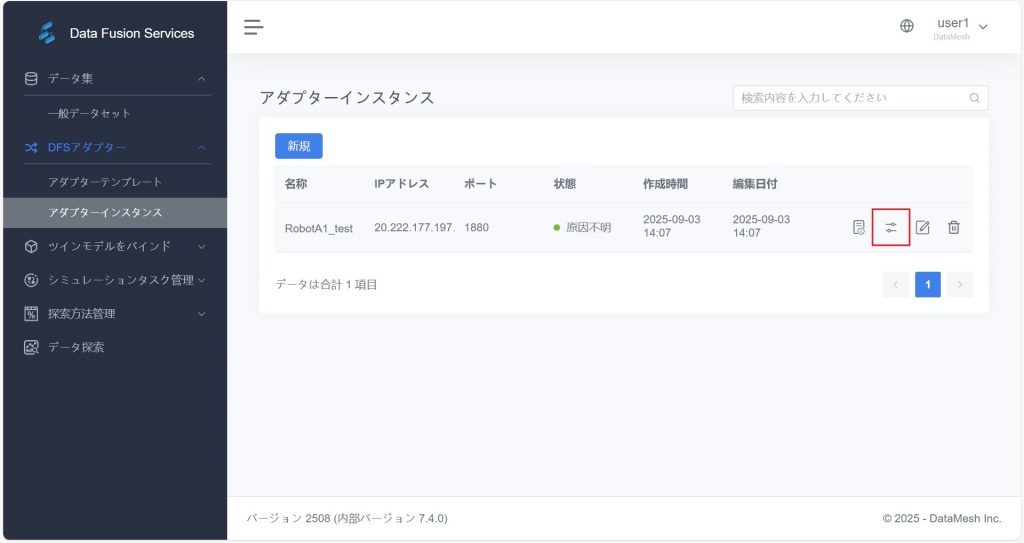
アダプタテンプレートのバインド(任意)
DFS アダプタ > アダプタインスタンス ページで、対象のアダプタインスタンスの【テンプレートを選択】ボタン をクリックし、アダプタテンプレートを選択してアダプタインスタンスにデータ処理ルールを設定します。
Node-RED フローの編集
本節では、企業内の開発エンジニアが、既に導入済みの DFS Node-RED 環境において、具体的な業務要件に応じて安全かつ効率的にデータフローを修正・拡張・更新する方法を説明します。
一、前提条件
編集を行う前に、以下の条件を満たしていることを確認してください:
- Node-RED が正常にデプロイされ、ブラウザ経由でアクセス可能であること(デフォルトアドレス: http://<server-ip>:1880)。
- Node-RED の基本概念(ノード、接続線、デプロイボタン)を理解していること。
- DFS プラットフォームのアカウントおよび主要なデバイス情報(例:edgeId、digitalTwinId)を取得済みであること。
- フローファイルのバックアップを取得済みであること(「JSON エクスポート」方式推奨)。
二、フロー構成の概要
DFS Node-RED フローは通常、以下の 3 つの主要部分で構成され、相互に連携して動作します:
- DFS ハートビートフロー:DFS プラットフォームへ定期的に「生存ハートビート」を送信し、ノードのオンライン状態を確認。
- デバイスバインドフロー:Redis からデバイスとデジタルツインのマッピング関係を取得し、グローバルキャッシュに保存。
- デバイスデータ送信フロー:デバイスの生データを受信またはシミュレーションし、マッピング関係に基づいて対応するデジタルツインへ送信。さらに MQTT を介して DFS Server(バックエンド保存用)およびフロントエンド(可視化駆動用)へ送信。
三、主要パラメータの説明:
パラメータ名 | 説明 | 例 | 注意事項 |
edgeId | エッジノードの一意識別子(DFS割当) | 68979c3e78f3d473c54e0cd9 | プラットフォーム情報と一致させる必要あり |
edgeName | ノード表示名(識別用) | nodered | 任意設定可、識別用に推奨 |
DFS ハートビート API URL | ハートビート送信先のアドレス | https://<dfs-server>/api/dfs/instance/beat | 必須、プラットフォーム設定と一致させる |
tenantId | テナントID | c299600a2e86b582746956d23e132b690 | プラットフォーム担当者に確認が必要 |
digitalTwinId | デジタルツイン一意識別子 | 600ab3a6391d44c499da0babe90f9e1f | DFS プラットフォームの孪生体詳細画面で取得可 |
四、データトピック
Node-RED フローは、以下の異なるトピックを通じてバックエンドおよびフロントエンドへデータを送信します:
- /DFS/telemetry/{edgeId}:DFS Server(Artemis)へテレメトリデータを送信。
- /DFS/{tenantId}/{digitalTwinId}:フロントエンド(EMQX 経由)へ孪生体駆動データを送信し、リアルタイムでのデジタルツイン表示を実現。
五、データフォーマット要件
DFS インターフェースが受信するデータは通常 JSON 形式であり、以下の構造を推奨します:
[ { “serial”: “Device name”, “ts”: 63, “datas”: { “key1”: “data1”, “key2”: “data2” } } ] |
フィールド説明:
- serial:デバイス名またはシリアル番号(バインディング関係と一致させる必要あり)。
- ts:タイムスタンプ(ミリ秒)。
- datas:デバイス属性と対応する値のキー・バリューペア。
⚠️注意事項:
- datas 内の属性名は、DFS プラットフォームに設定されているデジタルツインの属性と一致している必要があります。名前が一致しない場合、プラットフォームが提供する手動バインディング機能で属性マッピングを行ってください。
六、よくある業務修正ポイント
以下は、業務要件に応じてフローを調整する際に最も頻繁に使用されるノードタイプと、修正可能なパラメータの例です:
ノードタイプ | 用途 | 修正可能なパラメータ | 修正例 |
Inject | 定期トリガー(ハートビート / データ収集) | トリガー間隔 | ハートビート 10 秒ごと、データ収集 1 秒ごと |
File in | ファイルからデータを読み込み | ファイルパス | /home/user/device.json |
MQTT in | MQTT からデータをサブスクライブ | Broker アドレス、Topic | mqtt://192.168.1.100:1883, robot/pose |
Kafka in | Kafka からデータをサブスクライブ | Broker アドレス、Topic | kafka://broker1:9092, device-data |
Function | データ形式のクリーニング、フィールドマッピング | JS スクリプトロジック | temp:28.5C を { “temperature”: 28.5 } に変換 |
HTTP request | DFS へのデータ送信 | URL | https://<dfs-server>/api/dfs/data |
MQTT out | データをメッセージキューに転送 | Broker アドレス、Topic | ws://192.168.2.80:83 / 192.168.2.60:1884 |
七、接続設定
以下の接続ノード設定が正しく行われていることを確認してください。特に テスト環境/本番環境 への切り替え時に注意が必要です:
- MQTT out(フロントエンド用)
例:ws://192.168.2.80:83
設定名:emqx-mqtt
- MQTT out(DFS Server)
例:192.168.2.80:1884
設定名:artemis-mqtt
- Redis データソース
例:192.168.2.80:6379
デバイスとデジタルツインのバインディングマッピングを定期的に取得するために使用(キー名の形式:dfs:device:<serial>)
ツインモデルの関連付け
ツインモデル関連付けモジュールは、物理デバイスのデータをデジタルツインモデルにマッピングし、データ駆動型のシミュレーション、インタラクション、業務最適化を実現します。本機能により、企業は実際の稼働状態に近いツインモデルを構築し、運用保守、モニタリング、分析を支援できます。
デジタルツインシーンのインポート
対象となるツインモデルを含むシーンを FactVerse プラットフォームから DFS にインポートし、その後のデータ関連付けのためのベースとして使用します。
操作手順
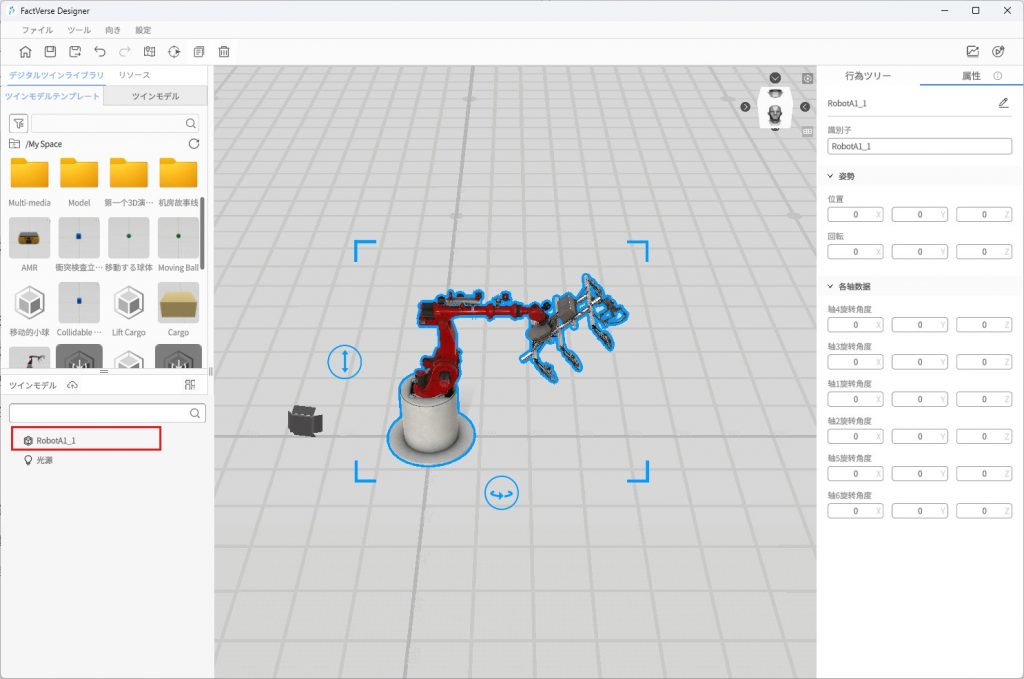
- デジタルツインシーンを作成:FactVerse Designer を使用してデジタルツインシーンを作成し、シーン内に実際のデバイスに対応するツインモデルが含まれていることを確認します。
例:シーン「ロボットアームDemo」を作成し、その中にロボットアームのツインモデル(例:“ロボットアームA1″)を含め、後続のデバイスデータ関連付けに使用します。
- デジタルツインシーンのインポート
a) DFS 管理プラットフォームにログインします。
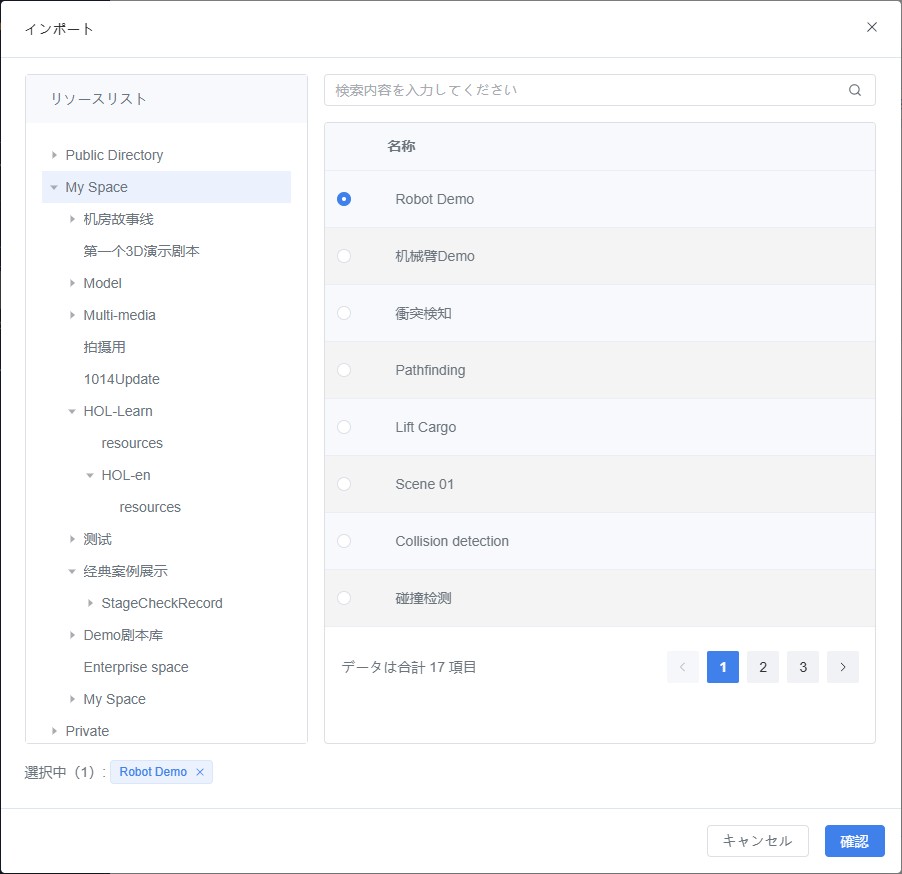
b) 「ツインモデル関連付け > シーン設定」ページで【インポート】をクリックし、インポートウィンドウを開きます。
c) インポートウィンドウで、インポートしたいシーン(例:「ロボットアームDemo」)を選択し、【確認】をクリックしてインポートを完了します。
デバイスとツインモデルのバインド
実際のデバイスとデジタルツインをバインドすることは、「データ駆動型の仮想シミュレーション」と「リアルタイム同期」を実現するための重要なステップです。バインドが完了すると、デバイスデータがツインモデルの属性変化を駆動し、リアルとバーチャルの閉ループ連動を形成します。
前提条件
- バインド対象のツインモデルを含むシーンをすでにインポート済みであること。
- デバイスの追加を完了していること(詳細は下記参照)。
デバイス追加方法
追加方法 | 説明 |
デバイスバインドページでインポート | 実デバイスまたはシミュレーションデータに接続するために手動でデバイスを作成 |
アダプターインスタンス作成時にインポート | リアルタイムデータを接続する過程で、自動的にデバイス情報を作成 |
デバイスとツインモデルのバインド手順
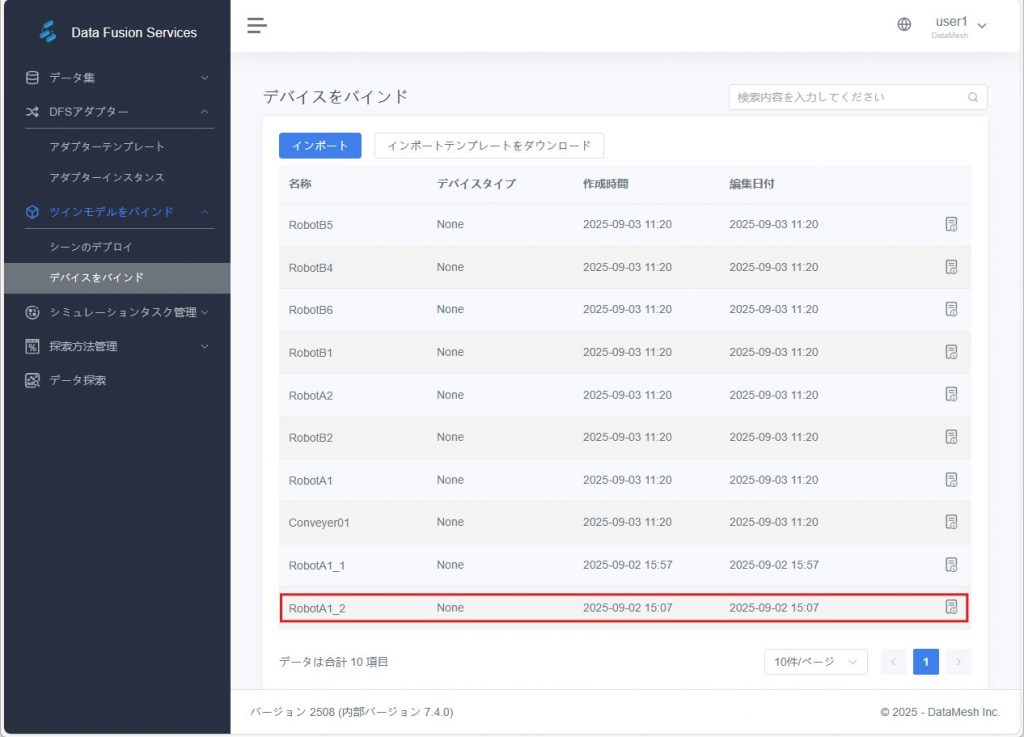
- デバイス詳細ページに入る:「ツインモデル関連付け > デバイスバインド」ページで対象デバイス(例:シミュレーションタスク作成時にインポートしたデバイス「RobotA1_2」)を見つけ、デバイスの詳細ページに入ります。
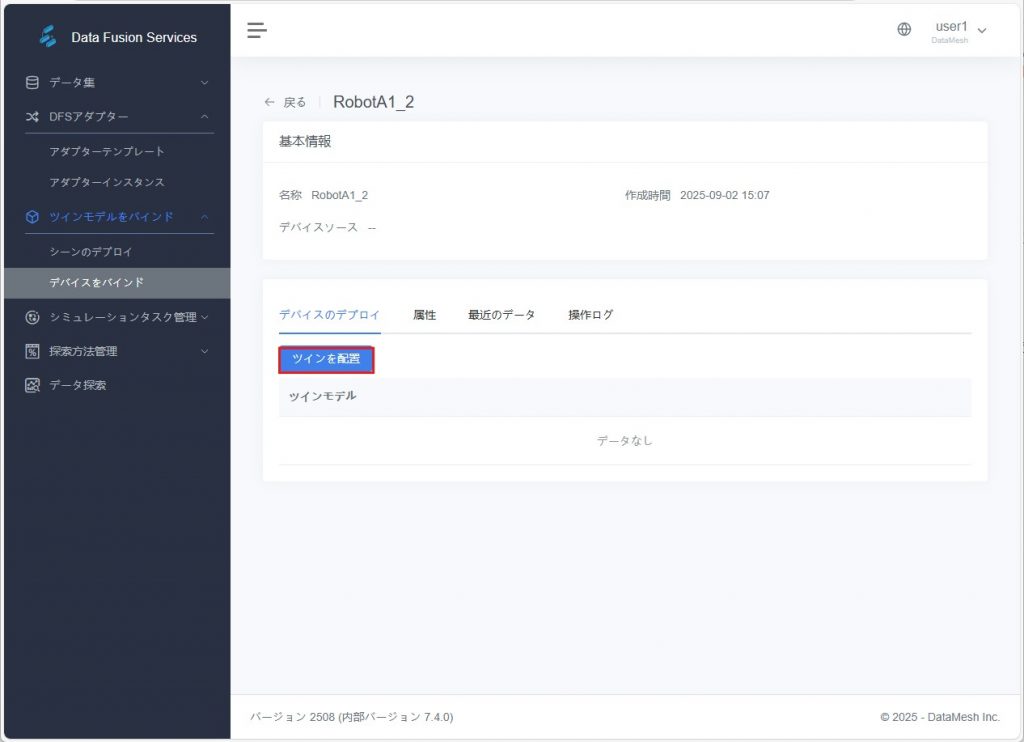
- ツインモデル設定ウィンドウを開く:デバイス設定欄で【ツインモデルを設定】ボタンをクリックし、ツインモデル設定ウィンドウを開きます。
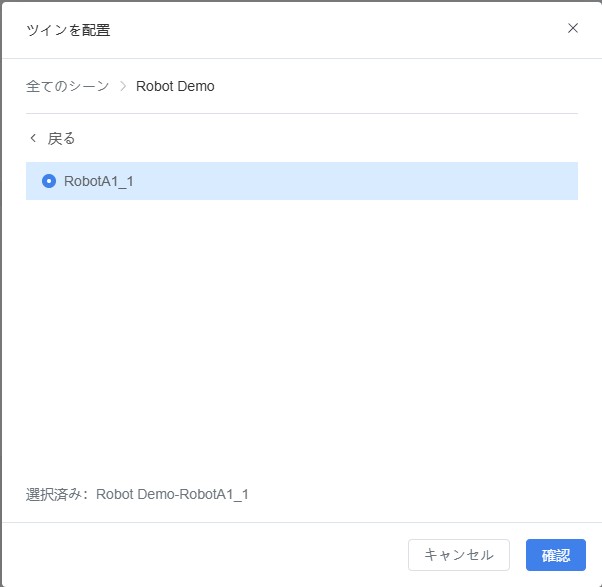
- ツインモデルを選択:
a) ツインモデル設定ウィンドウで、デバイスが属するシーンの下位ボタンをクリックします。
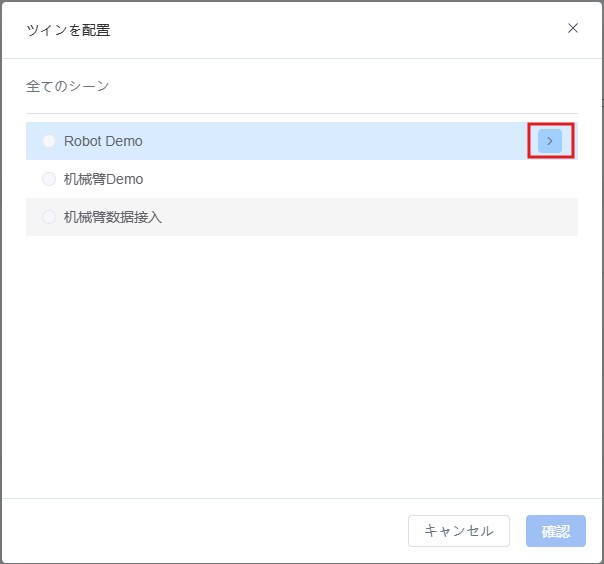
b) バインドするツインモデルを選択し、【確認】をクリックしてデバイスとツインモデルのバインドを完了します。
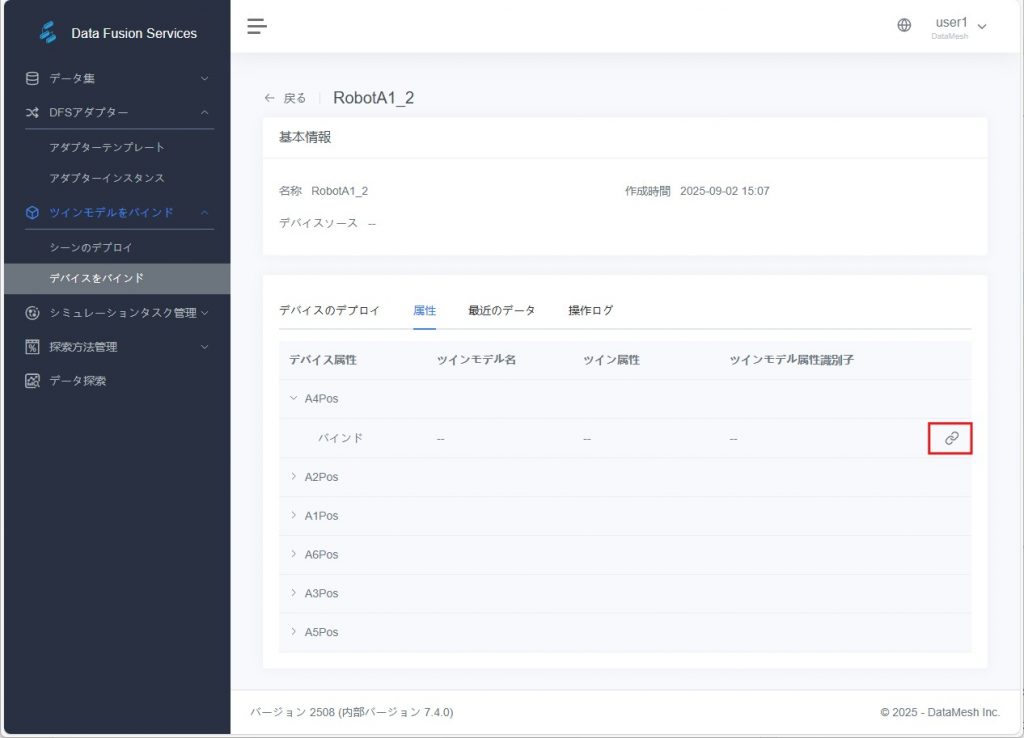
- 属性バインド(任意):
デバイス属性とツインモデル属性の名称が一致しない場合は、手動でバインドを行い、データが正しくツインモデル属性の変化を駆動するようにします。
a) 属性タブをクリックし、デバイス属性のバインドアイコン をクリックします 。
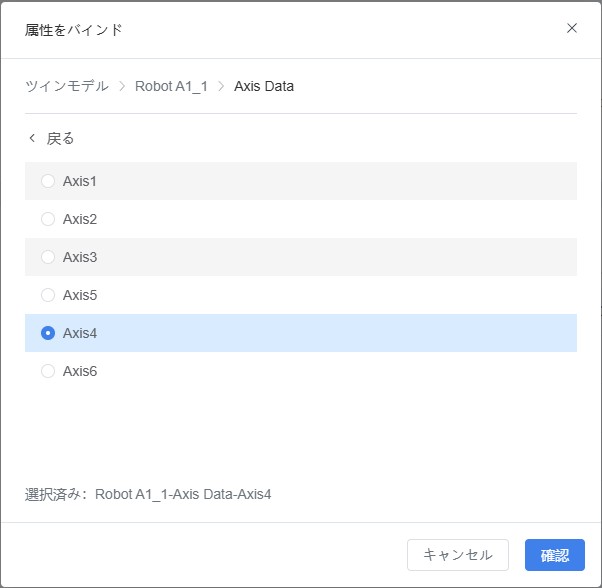
b) ポップアップされた「属性バインド」ウィンドウで、関連付けたい属性を選択し、【確定】をクリックします。
検証: FactVerse Designer でシーン「ロボットアームDemo」を開きます。【再生】ボタンをクリックし、データにより駆動されたロボットアームの姿勢変化を確認します。
データセット管理
データセット管理モジュールは、ユーザーに対して統一されたデータのインポート、整理、分類、分析サポートを提供し、データ探索、インテリジェント分析および可視化を行うための基盤となります。
共通データセットページ
共通データセットページは、さまざまなソースからのデータリソースを集中管理し、その後のデータ探索やモデリング分析を支援します。
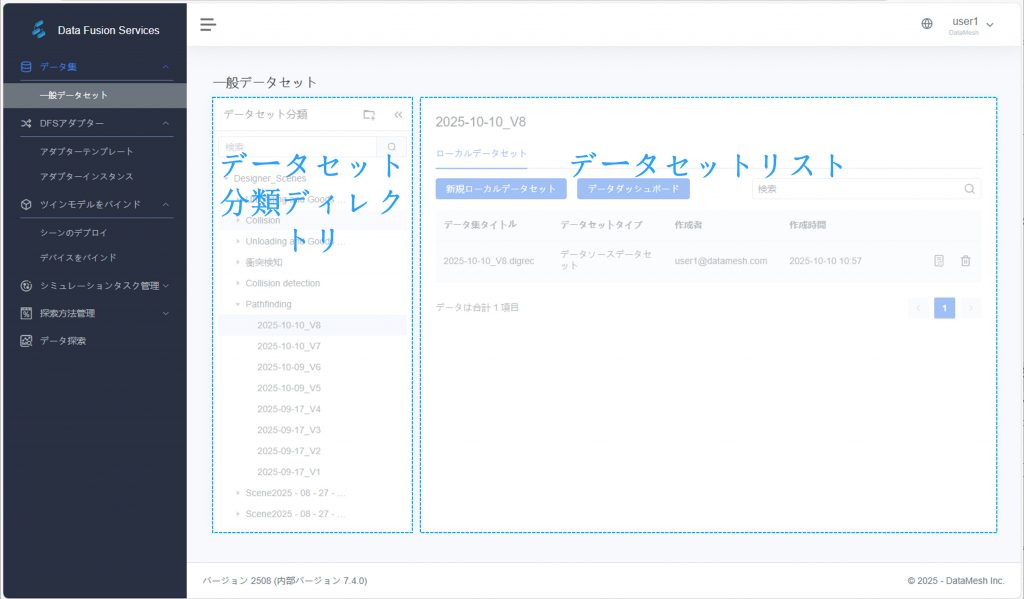
データセット分類ディレクトリ
左側にはデータセットの分類ディレクトリがあり、データセットをグループ管理することができます。これにより、データ処理フロー全体の追跡や構造化された整理が可能となります。
操作説明
操作 | 説明 |
サブカテゴリを追加 | カテゴリ名にマウスをホバーし、【サブカテゴリを追加】ボタンをクリックしてサブディレクトリを作成 |
カテゴリ名を変更 | カテゴリ名にマウスをホバーし、【編集】ボタンをクリックして名称を変更 |
カテゴリを削除 | サブカテゴリを持たない空のカテゴリのみ削除可能。サブカテゴリが存在する場合は、先に削除する必要があります ※注意:カテゴリを削除すると、その配下のすべてのデータセットが削除されます。復元できないため注意が必要です |
カテゴリ検索 | キーワードによるあいまい検索に対応し、目的のカテゴリを素早く特定可能 |
データセットリスト
左側の分類ディレクトリでカテゴリを選択すると、右側にそのカテゴリ配下のすべてのデータセットが表示されます。表示される項目は以下の通りです:
- データセット名
- データセットタイプ(ローカルデータセット / データソースデータセット / 探索データセット)
- 作成者
- 作成日時
データセットタイプ
共通データセットはソースによって3種類に分類されます:
タイプ | 説明 | 適用シーン |
ローカルデータセット | ユーザーが手動でアップロードした .csv ファイル | オフラインデータの迅速なインポートと分析 |
データソースデータセット | 外部業務システムから接続されたデータ、または FactVerse Designer から生成・アップロードされたシミュレーション記録 | 行動シミュレーション、生産モニタリング、デジタルツインのデータ駆動など |
探索データセット | 自動または手動のデータ探索タスクによって生成された結果データセット | データ分析、アラートルール設定、および結果出力 |
データセットリストエリアの機能説明
機能 | 説明 |
新規ローカルデータセット | 【新規ローカルデータセット】をクリックし .csv ファイルをアップロード。システムが自動的に解析してデータセットを作成 |
データダッシュボード | 【データダッシュボード】をクリックしてデータ可視化の設定・表示画面に入り、グラフ設定やインタラクティブ分析を実行可能 |
データセット検索 | データセット名、タイプ、時間範囲などで対象データセットを迅速に検索 |
データ閲覧 | データセットの詳細ボタンをクリックし、データビュー画面で分析やデータ表の閲覧などを実行 |
データセット削除 | 選択したデータセットを削除(復元不可のため注意) |
ローカルデータセットの作成
共通データセットページでは、ユーザーは .csv ファイルをアップロードすることで迅速にローカルデータセットを作成できます。これにより、その後のデータ分析タスクが容易になります。
操作手順
- データセット分類の選択:左側の分類ディレクトリで、新しいデータセットを所属させたいカテゴリを選択します。適切な分類がない場合は、新規にカテゴリディレクトリを作成してから続行します。
- 【新規ローカルデータセット】をクリック:画面右上の【新規ローカルデータセット】ボタンをクリックし、新規作成ウィンドウを開きます。
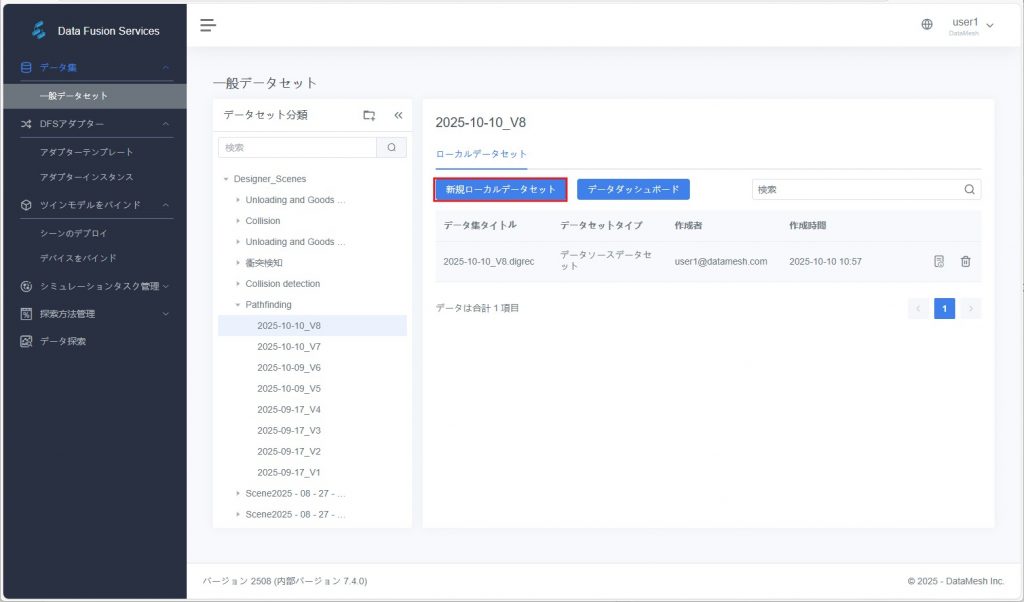
- データセットの基本情報を入力:表示されたウィンドウで、以下の情報を入力します:
- データセット名
- 説明(任意)
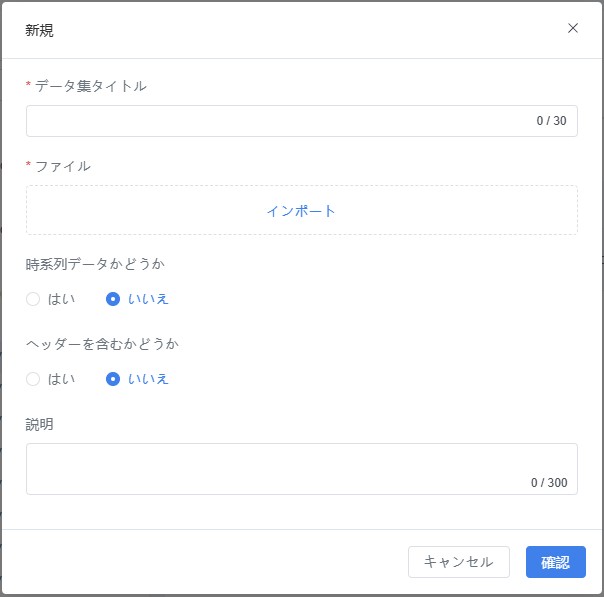
- CSV ファイルのインポート:[ファイルをインポート]をクリックし、ローカルの .csv ファイルを選択してアップロードします。
注意:CSV ファイルの形式が要件を満たし、フィールド形式が正しく、データが完全であることを確認してください。そうでないと、インポートが正常に行えない可能性があります。
- 以下のデータセットオプションを設定:
- 時系列データかどうか:データにタイムスタンプが含まれ、時間順に分析する場合は「はい」にチェックします。例:ある装置が5分ごとに回転数を収集するケースは典型的な時系列データです。
- ヘッダーを含むかどうか:CSV ファイルの1行目がフィールド名である場合は「はい」にチェックします。それ以外の場合は「いいえ」にチェックします。
- [確認]をクリックして完了:システムが自動的に CSV の内容を解析してデータフィールドを生成します。データセットが正常に作成されると、現在の分類ディレクトリに表示されます。
データ閲覧
通用データセットページで任意のデータセット名、または右側の詳細ボタンをクリックすると、そのデータセットの閲覧・分析画面に入ることができます。
データ閲覧ページには「データ表」「データ分析」「フィールド管理」の3つのタブがあり、ユーザーは異なる観点からデータを閲覧・フィルタリング・分析することができます。これによりデータの規則性を発見し、後続のデータモデリングやアラート設定などの操作の基礎データを提供します。
データ表
通用データセットから対象データセットを選択し、データセット名または詳細ボタンをクリックしてデータ閲覧ページに入ります。システムはデフォルトで「データ表」タブを開きます。
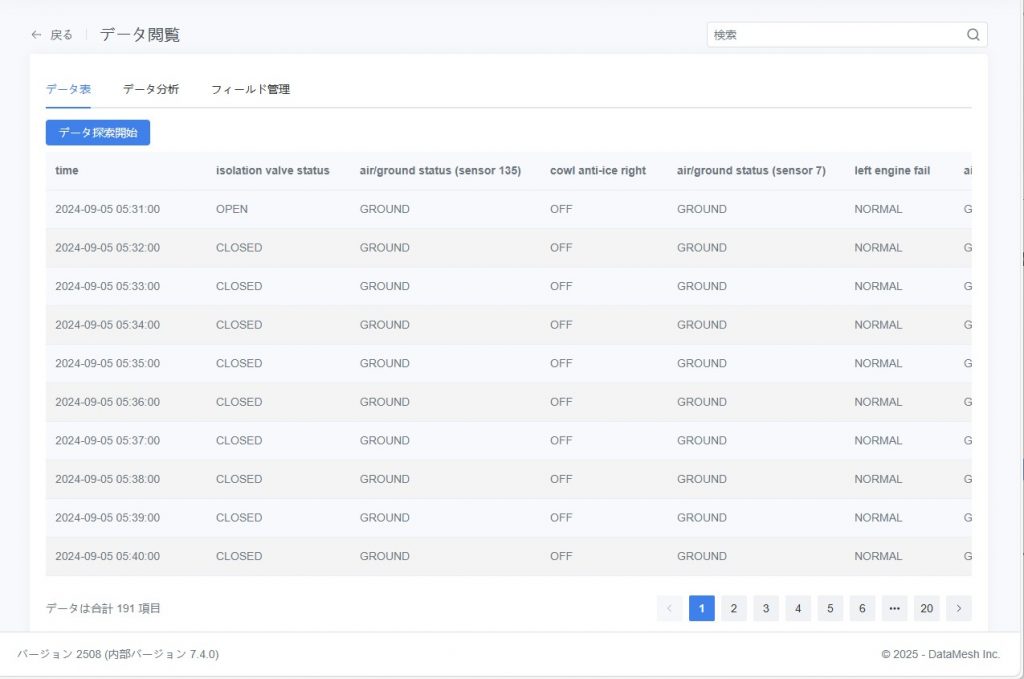
このタブは表形式で元データを表示し、以下の用途に適しています:
- 個々のデータポイントの値を正確に確認する
- 複数パラメータの具体値を比較する
- 時系列でデータの変化を確認する
機能説明
- 表はデフォルトで時系列昇順に並び替えられ、必要に応じてパラメータでフィルタリングできます。
- 各行データには選択したパラメータの具体値が含まれます。フィールド名は「フィールド管理」タブで管理・別名設定が可能です。
- 時間やパラメータなどのフィールドごとに逐次データを閲覧できます。
- このタブから直接「データ探索」タスクを開始し、特定のデータポイントや時間帯を分析できます(「データ探索の開始」参照)。
パラメータフィルタリング操作手順
- 「データ表」タブ右上のフィルターボックスをクリックします。
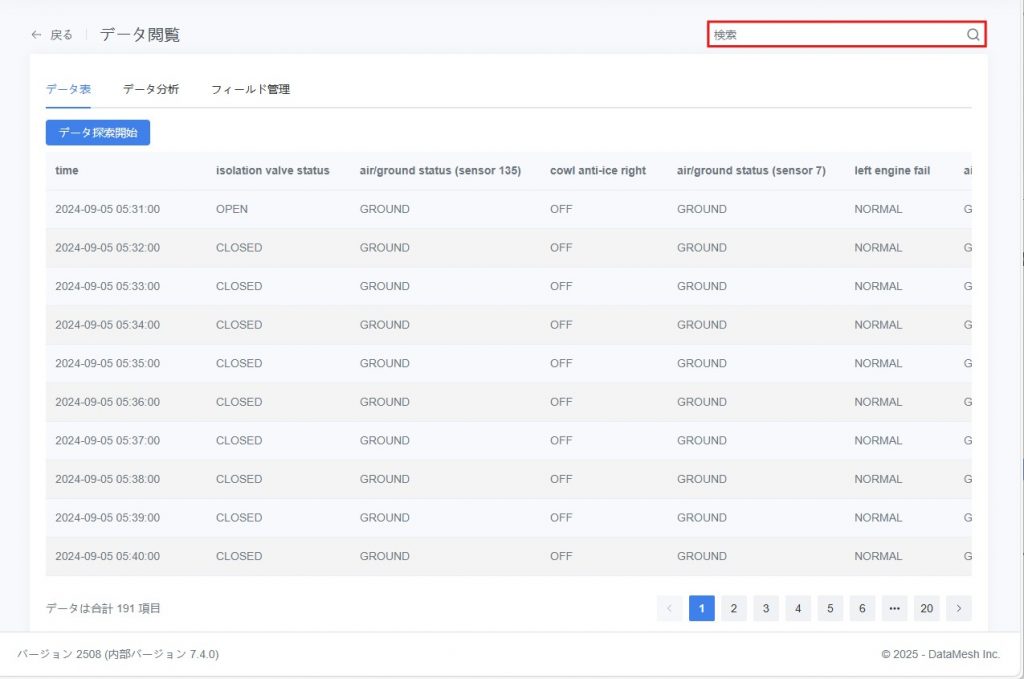
- ポップアップした「パラメータフィルタ」ウィンドウで【パラメータを選択】ボタンをクリックします。
- 「パラメータを選択」ウィンドウで表示したいパラメータにチェックを入れ、【確認】をクリックします。
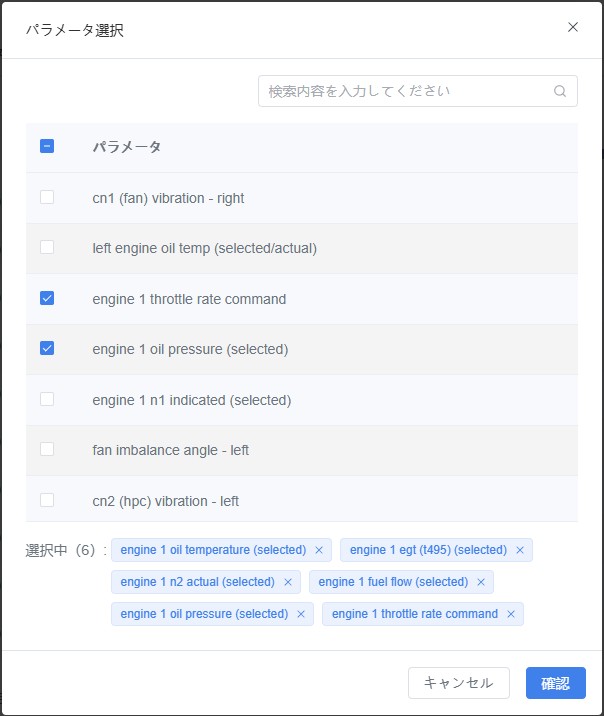
- データ表には選択したパラメータフィールドのみが表示されます。
データ分析
「データ分析」タブは、単一の「時系列データセット」に対する探索・分析に用いられ、チャートを設定することでユーザーがトレンド、異常、あるいは変数間の関係を発見するのに役立ちます。
機能説明
- パラメータフィルタで分析対象のフィールドを選択可能。
- 散布図、折れ線グラフ、ヒストグラムなど、複数のグラフタイプをサポート。
- フィールドのスタイル設定、特徴点(最大値・最小値・中央値など)のラベル表示に対応。
- インタラクション操作に対応:拡大・縮小、ドラッグ、補助線、データヒント、時間範囲の選択。
- グラフを画像としてエクスポートし、レポートや共有に活用可能。
ヒント:初回アクセス時は未設定の場合、ページは空白です。すでに設定済みの場合、システムが前回のグラフを自動的に読み込みます。

操作手順
- データ分析に入る:共通データセットで対象データセットをクリックし、データ閲覧ページで「データ分析」タブに切り替えます。
- パラメータをフィルタしてグラフを生成:
- ツールバー内の「フィルタ」ボックスをクリックします。
a) ポップアップした「パラメータフィルタ」ウィンドウで【パラメータ選択】をクリックし、グラフ生成に使用するフィールドを選択します。
b) 【送信】をクリックすると、システムが自動的にデフォルトの折れ線グラフを生成します。
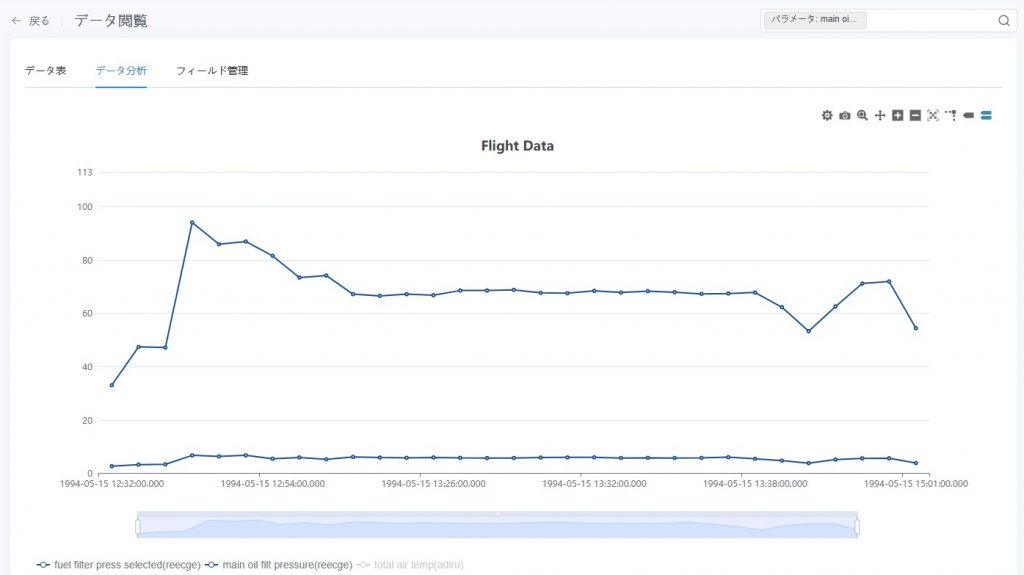
- グラフの設定
散布図・折れ線グラフなどのグラフタイプを手動で設定し、関連パラメータを選択してグラフ表示を最適化できます。
ツールバーの【データ設定】ボタン![]() をクリックし、パラメータ設定ウィンドウを開きます。
をクリックし、パラメータ設定ウィンドウを開きます。
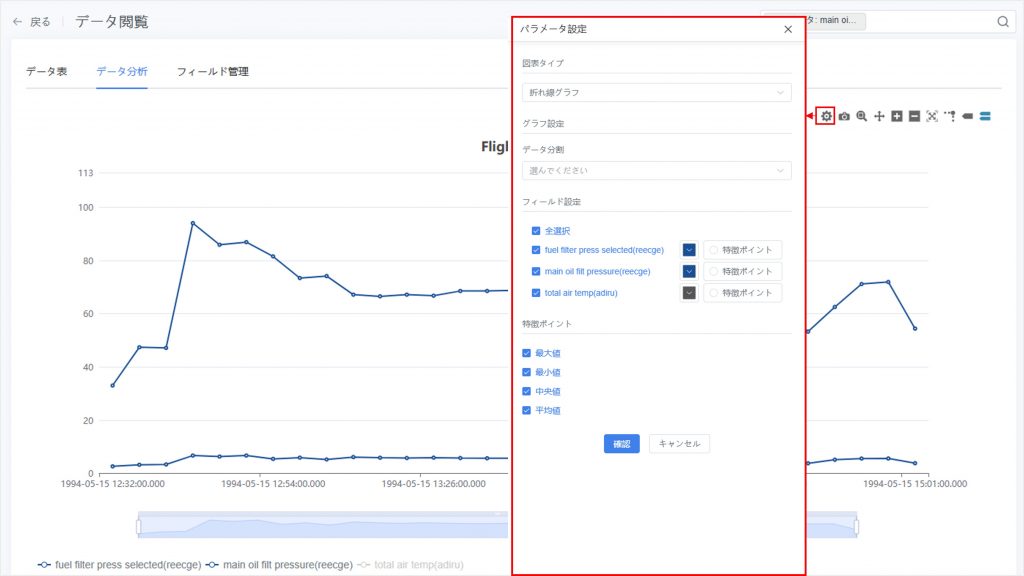
- グラフタイプ:散布図、折れ線グラフ、ヒストグラムから選択。
- データ分割:分析対象のパラメータを選択し、独立したグラフを生成。
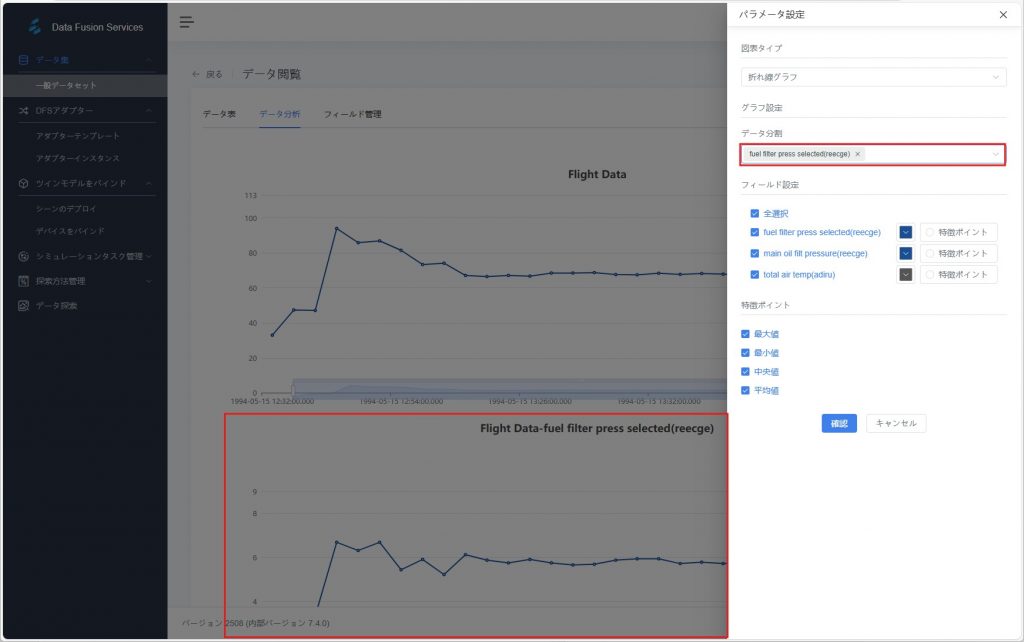
- フィールド設定:
- 表示したいフィールド(パラメータ)にチェックを入れ、グラフ上での色やラベルを調整できます。
- フィールドのスタイル(色、線種など)を変更し、グラフの可読性を向上させることができます。
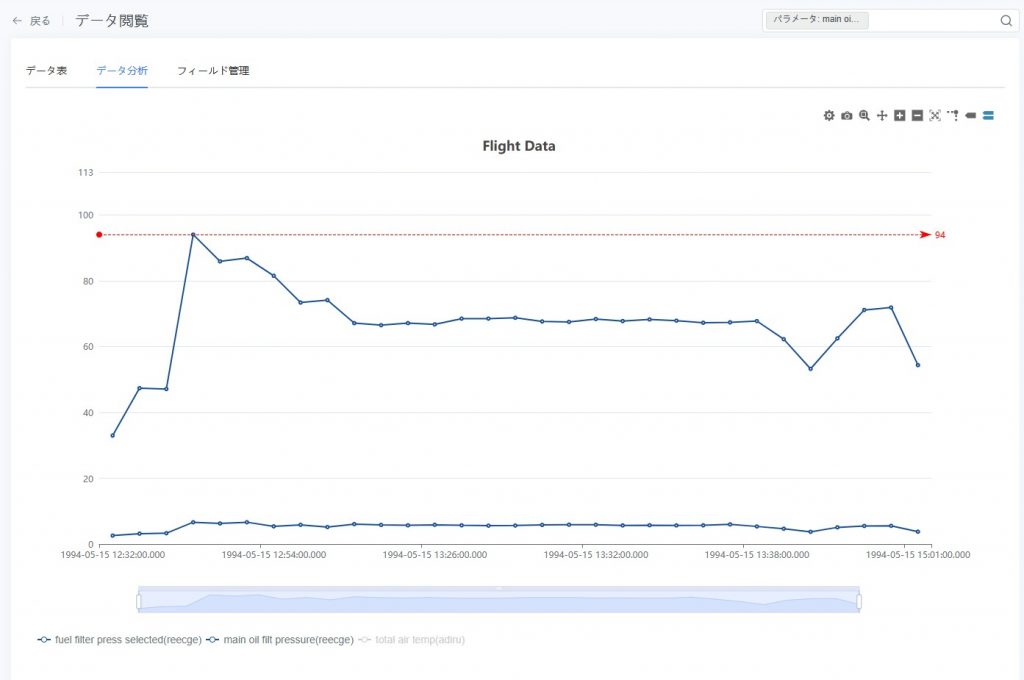
- 特徴点の注釈(オプション):「フィールド設定」で「特徴点」オプションを有効にすると、分析上重要なデータポイント(例:異常値、閾値点など)をグラフ上にマークできます:
- 最大値:データのピークをマークし、異常に高い値を識別するのに役立ちます。
- 最小値:データの最低点をマークし、トレンドの谷を分析するのに使用します。
- 中央値:データの中央値を表示し、全体の分布の中心傾向を把握するのに役立ちます。
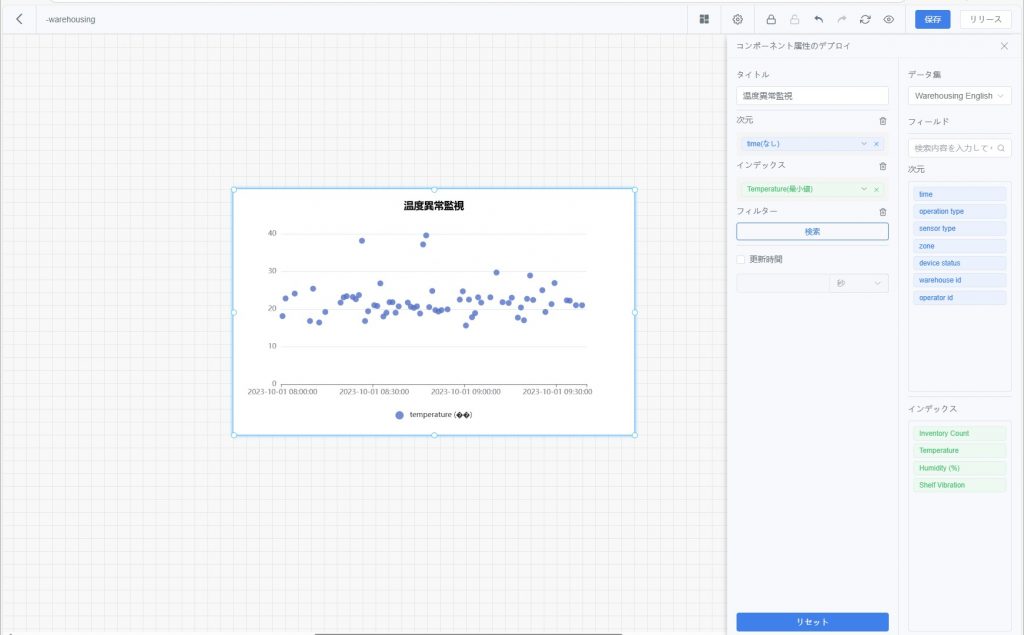
下図は、パラメータ「排気温度 EGT(右エンジン)」の特徴点 最大値 を示しています。
- インタラクションと閲覧
生成されたグラフに対して、ユーザーは以下のインタラクション操作を行い、柔軟にデータを確認・分析できます:
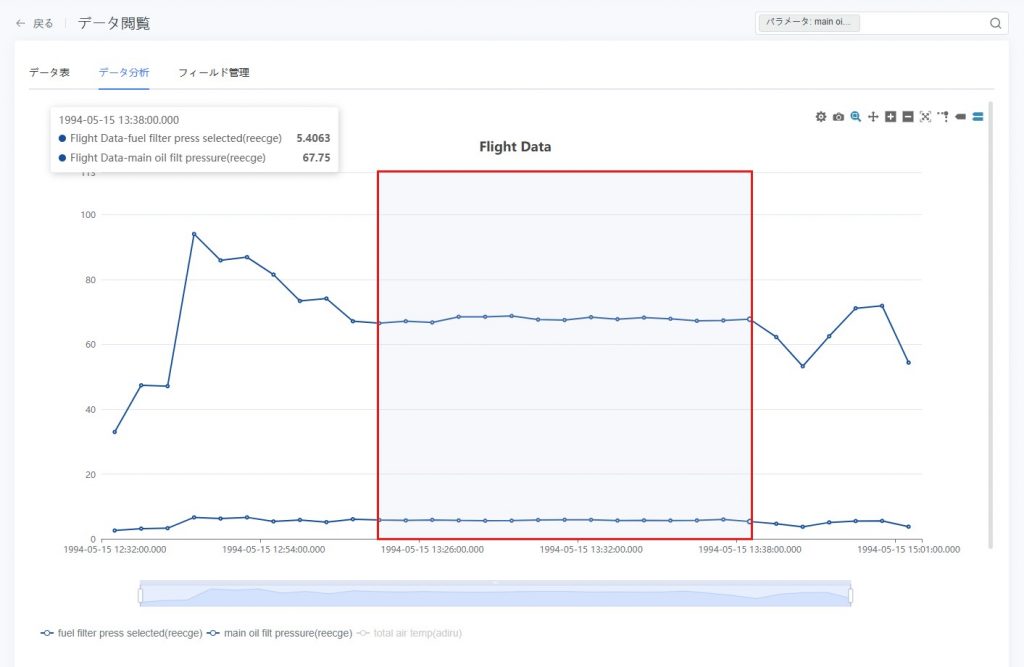
- ズームと移動
- 【ズーム選択】ボタン
 をクリックし、マウスで 左上から右下 にドラッグしてグラフの特定領域を囲むと、そのデータ区間を拡大表示できます。右下から左上 にドラッグすると、直前のズーム操作を取り消すことができます。
をクリックし、マウスで 左上から右下 にドラッグしてグラフの特定領域を囲むと、そのデータ区間を拡大表示できます。右下から左上 にドラッグすると、直前のズーム操作を取り消すことができます。
- 【ズーム選択】ボタン
- ズームイン
 / ズームアウト
/ ズームアウト :ズームボタンでグラフの倍率を調整し、データをより詳細に確認できます。
:ズームボタンでグラフの倍率を調整し、データをより詳細に確認できます。 - ドラッグ
 :マウス左ボタンを押したままグラフをドラッグすることで、表示領域を移動し、別の部分を確認できます。
:マウス左ボタンを押したままグラフをドラッグすることで、表示領域を移動し、別の部分を確認できます。 - ビューをリセット
 :【リセット】ボタンをクリックすると、グラフは初期の表示サイズとデータの時間範囲に戻ります。
:【リセット】ボタンをクリックすると、グラフは初期の表示サイズとデータの時間範囲に戻ります。
- 補助分析
- 補助線
 :マウスをグラフ上の任意のデータ点にホバーすると、縦横の補助線が表示され、数値を正確に比較するのに役立ちます。
:マウスをグラフ上の任意のデータ点にホバーすると、縦横の補助線が表示され、数値を正確に比較するのに役立ちます。
- 補助線
- 単列
 / 複数列のツールチップ
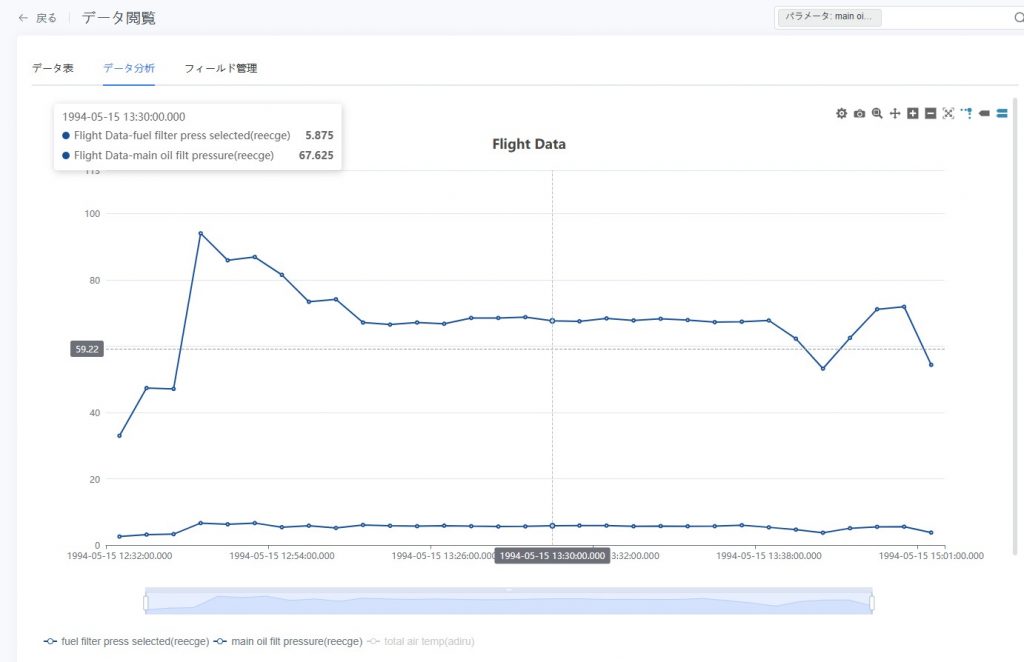
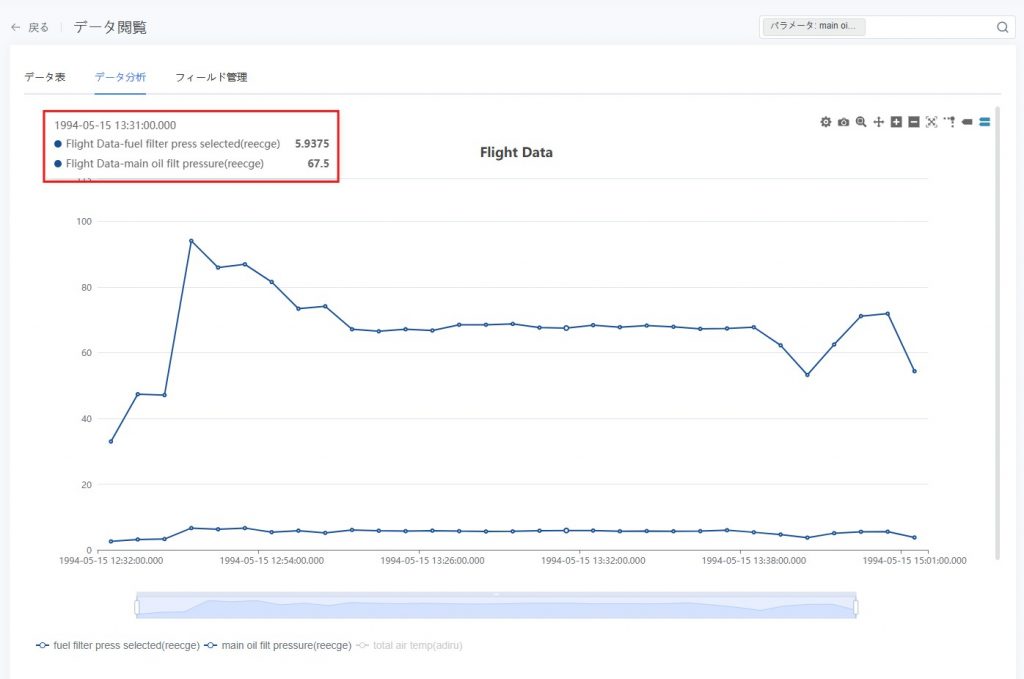
/ 複数列のツールチップ :マウスをデータ点にホバーすると、その時点における1つまたは複数の縦軸パラメータの数値情報が表示されます。
:マウスをデータ点にホバーすると、その時点における1つまたは複数の縦軸パラメータの数値情報が表示されます。
- 時間区間の選択
- 表示範囲の調整:「時間範囲セレクター」の開始・終了ハンドルをドラッグして、表示する時間区間を左右に調整できます。
![]()
- 時間区間の選択:選択済みの時間範囲内で、マウス左ボタンを押したままドラッグすると、新たに時間区間を選択できます。
![]()
- 時間区間の移動:「時間範囲セレクター」の上端にマウスを移動すると、カーソルが両方向矢印に変わります。そのままドラッグすると、区間の長さを変えずに全体を平行移動できます。
![]()
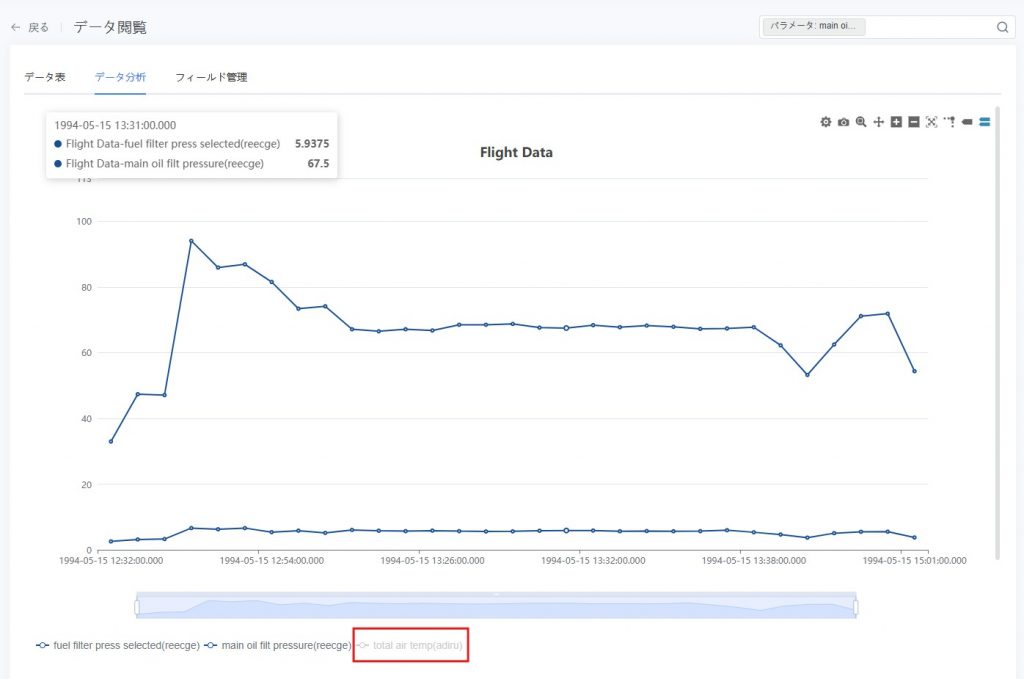
- フィールドの表示 / 非表示:グラフ下部のフィールド名をクリックすることで、そのフィールドの表示・非表示を切り替えることができます。
- 画像のエクスポート
 :【画像としてエクスポート】ボタンをクリックすると、現在のグラフを画像ファイルとして保存でき、後での共有やレポートに利用可能です。
:【画像としてエクスポート】ボタンをクリックすると、現在のグラフを画像ファイルとして保存でき、後での共有やレポートに利用可能です。
フィールド管理
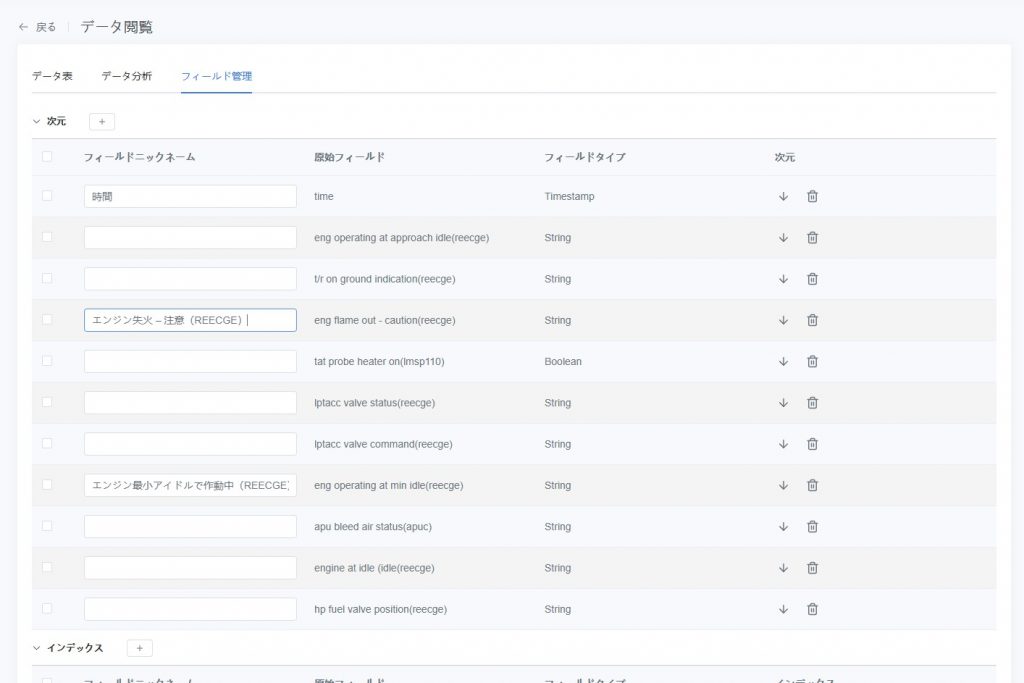
「フィールド管理」タブは、データセット内のフィールドの表示名や分類方法を管理するために使用されます。これにより、データ表やダッシュボードなどの機能でフィールドを素早く特定できます。
フィールド分類ルール
システムはデータセットのフィールドを自動的に分析し、「ディメンション」または「メトリクス」に分類します
- ディメンション:
- テキスト型:CHAR、VARCHAR、TEXT、MEDIUMTEXT、LONGTEXT、ENUM、ANY
- 時間型:DATE、TIME、YEAR、DATETIME、TIMESTAMP
- メトリクス:
- 整数型:INT、SMALLINT、MEDIUMINT、INTEGER、BIGINT、LONG
- 浮動小数型:FLOAT、DOUBLE、DECIMAL、REAL
- ブール型:BIT、TINYINT
サポートされる操作
- フィールドのニックネーム編集:フィールドに分かりやすい別名を付け、データ表やダッシュボードでの識別を容易にします。
- フィールドタイプの切り替え:
- 下向きアイコンをクリック → ディメンションをメトリクスに切り替え
- 上向きアイコンをクリック → メトリクスをディメンションに切り替え
注意:テキスト型ディメンション(システムで string タイプと識別されたもの)はメトリクスに変換できません。
- フィールド削除:単一または複数のフィールドを削除可能。
- フィールド追加:単一または複数のフィールドを追加可能。
以上の操作はすべてフィールドの表示と管理にのみ影響し、元のデータセットは変更されません。システムは編集のたびに自動で変更を保存します。
データダッシュボード
「データダッシュボード」は、複数の可視化グラフを一つのページに集約して表示・比較する機能です。これにより、トレンド分析、異常検知、レポートでの共有が容易になります。
「データ分析」が単一データセットに対する一時的な探索を重視するのに対し、データダッシュボードは複数のデータセットや異なるパラメータを組み合わせた統合的な可視化を実現します。
サポートされるグラフタイプ:経路分析、衝突統計、明細表、円グラフ、棒グラフ、散布図 など。
データソース範囲の説明
- システムが自動生成するシナリオディレクトリ:(例:「シミュレーションレビュー」で生成された「シナリオ名」分類ディレクトリ):
このディレクトリ配下のダッシュボードは、そのディレクトリ配下のデータセットのみを参照可能です。→ 同一シナリオでの複数回のシミュレーション結果比較に適用。 - 手動で作成した分類ディレクトリ:
このディレクトリ配下のダッシュボードは、任意の他ディレクトリ配下のデータセットを参照可能です。→ 異なるソースデータを組み合わせる分析シーンに適用。
データダッシュボード画面
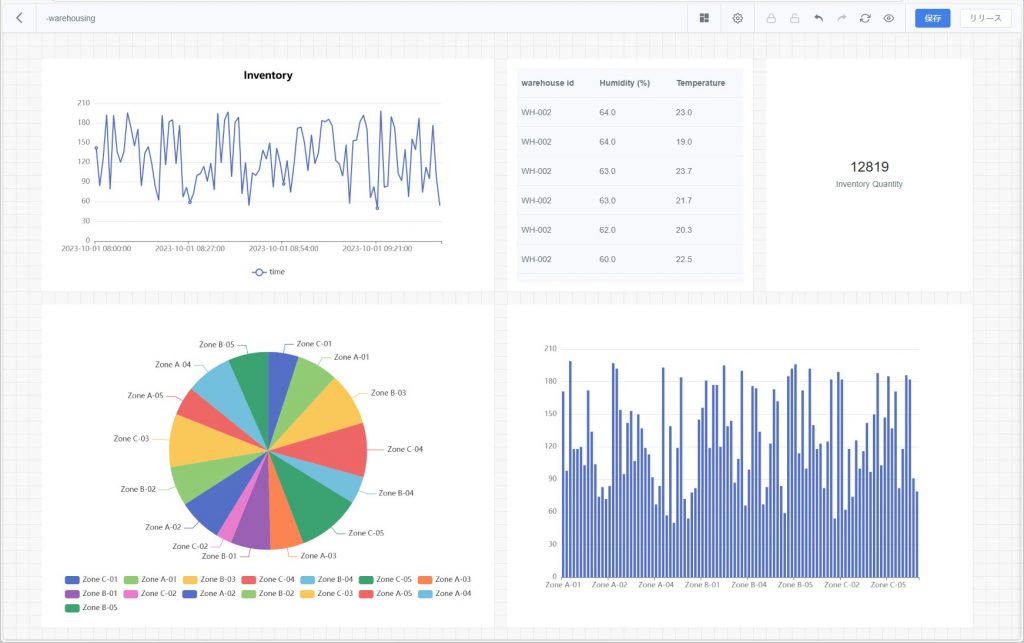
ダッシュボードツールバー

機能 | 説明 |
コンポーネントメニュー | 【コンポーネントメニュー】をクリックすると、ダッシュボードに追加するコンポーネントタイプを選択できます。例:統計指標、棒グラフ、円グラフ、折れ線グラフ、散布図、明細表、経路分析、衝突統計など。 |
設定 | 【設定】をクリックして、ダッシュボードのデータ更新頻度を設定します。 |
ロック | ダッシュボードをロックし、誤編集を防止します。 |
アンロック | ロック済みのダッシュボードを解除し、編集機能を復元します。 |
元に戻す | 直前の編集操作を取り消します。 |
やり直す | 最近の取り消し操作を復元します。 |
キャンバスをリセット | ダッシュボードのキャンバスを初期レイアウトに戻します。 |
プレビュー | 【プレビュー】をクリックすると全画面モードに切り替わり、ダッシュボードの表示効果を確認できます。 |
保存 | 現在のダッシュボード設定を保存し、後で編集や参照できるようにします。 |
公開 | 現在のダッシュボード設定を公開します。公開後、同じシナリオディレクトリ内で自動生成されたシミュレーションデータセットに対して、この設定を直接適用し、自動でダッシュボードを生成できます。 |
データダッシュボード作成フロー
初回設定時は、コンポーネントを手動で追加しデータセットにバインドする必要があります。その後は、ダッシュボードテンプレートを利用することで設定を効率的に再利用できます。
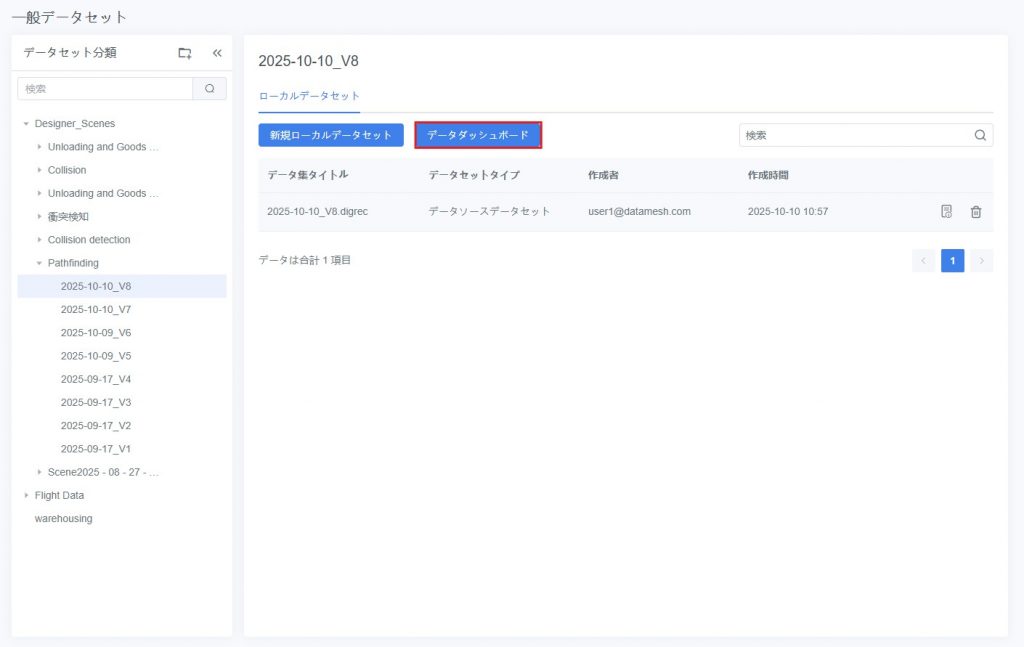
初回設定手順
- ダッシュボード画面を開く:データセット一覧から対象データセットを見つけ(例:Designer シミュレーションレビューで生成されたシミュレーション記録データセットや手動アップロードしたデータセット)、【データダッシュボード】をクリックし、空白のダッシュボードを開きます。
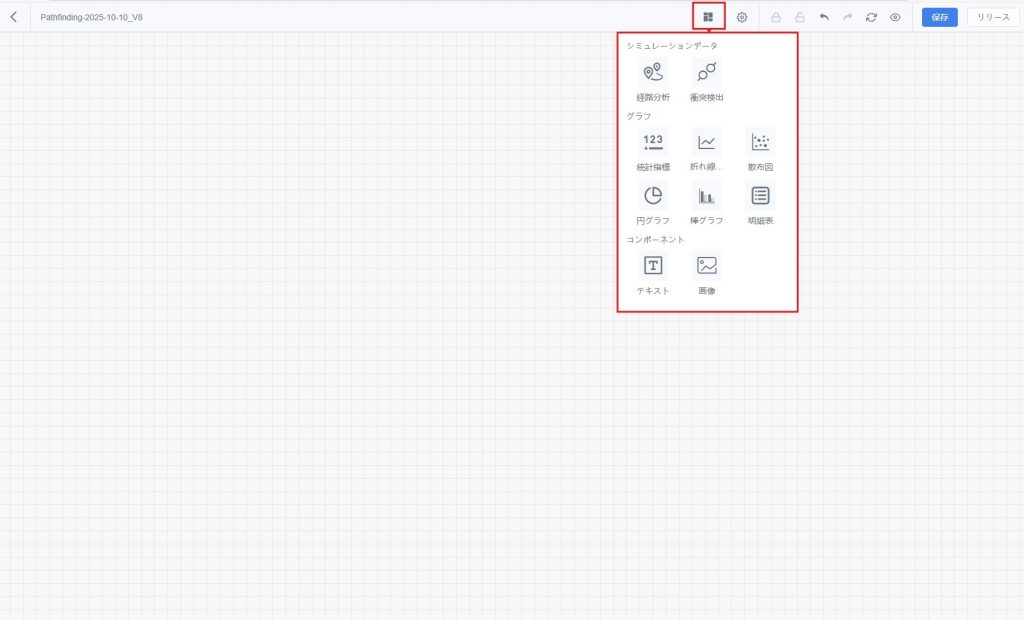
- コンポーネント追加:【コンポーネントメニュー】をクリックし、追加したいコンポーネントを選択してダッシュボードキャンバスに配置します。
- コンポーネント属性設定パネルを開く:追加したコンポーネントをダブルクリックすると、設定パネルが開き、データセット、フィールド、スタイルなどのパラメータを設定できます。
- ダッシュボード設定を保存:【保存】をクリックして設定を保存し、後で直接参照や編集ができるようにします。
- ダッシュボード公開(任意):後続の同一データ構造タスクで設定を再利用したい場合は、【公開】をクリックして現在のダッシュボードをテンプレートとして公開します。
自動テンプレート適用の条件
- Designer シミュレーションレビューに基づいて新しいシミュレーション記録が生成されると、DFS はその記録をデータセットとして保存し、対応するシナリオの分類ディレクトリに自動で整理します。
- 該当シナリオで既にダッシュボードテンプレートが公開されている場合、システムは新しいデータセットにテンプレート設定(コンポーネント配置、フィールドバインド、フィルター条件など)を自動適用し、新しいダッシュボードを生成します。
- ⚠️ 手動でアップロードしたローカルデータセットやその他のデータセットは、たとえフィールドが一致していても自動ではテンプレート適用されません。その場合は手動でダッシュボードに入り、データセットをバインドしてコンポーネントを設定する必要があります。
ダッシュボードコンポーネントの設定
経路分析
経路分析コンポーネントは、データダッシュボードで経路分析が可能なデジタルツインを確認し、その走行経路を Designer のシナリオ上に重ねて表示することで、データと 3D シナリオの直感的な連携を実現します。
機能説明
- コンポーネントを読み込むと、現在のデータセットおよびシナリオ内で経路分析に対応するすべてのデジタルツインがリスト形式で表示されます。
- ユーザーは Designer で 1 つ以上のデジタルツインを選択し、【3D 結果表示】をクリックすることで、該当シナリオを開き、走行経路を重ねて表示できます。
- Designer シミュレーションレビューに基づいて生成されたシミュレーション記録データセットのみをサポートします。
操作手順
- DFS で経路分析コンポーネントを設定:
a) データダッシュボードの【コンポーネントメニュー】から【経路分析】を選択し、キャンバスに追加します。
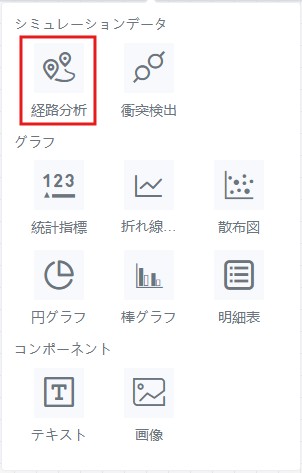
b) コンポーネントをダブルクリックし、右側の設定欄でバインドするデータセットを選択します(通常はシミュレーションレビューで生成されたデータセット)。
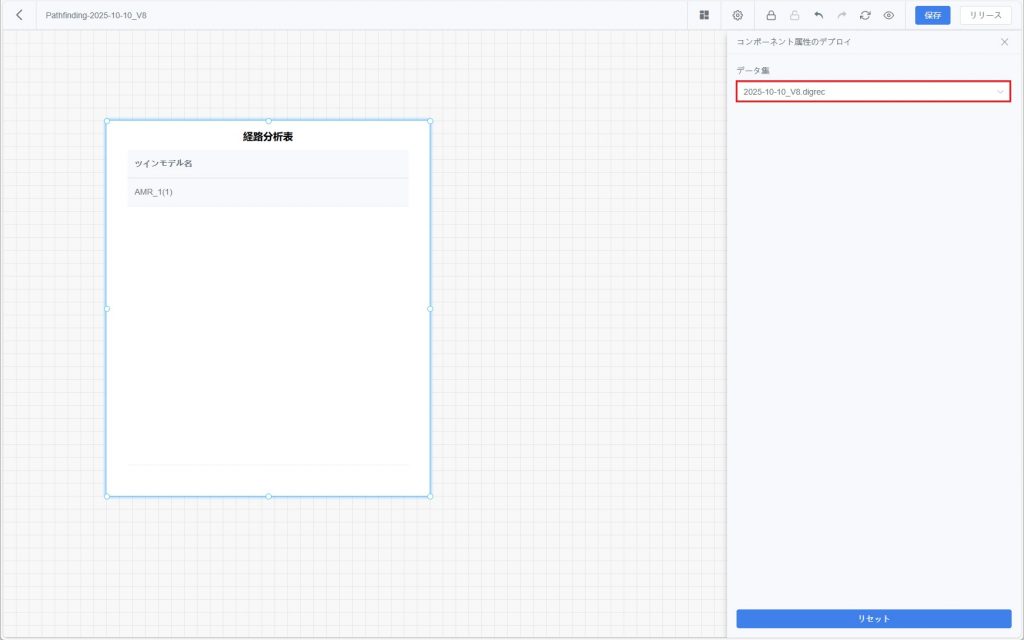
c) 【更新】をクリックして設定効果を確認し、【保存】をクリックしてダッシュボード設定を保存します。
- Designer で経路重ね合わせ効果を確認:
a) ホームページの【シミュレーションレビュー】ボタンをクリックし、DFS 通用データセットウィンドウを開きます。
b) データセット一覧から対象データセットを探し、【データダッシュボード】をクリックしてダッシュボード画面を開きます。
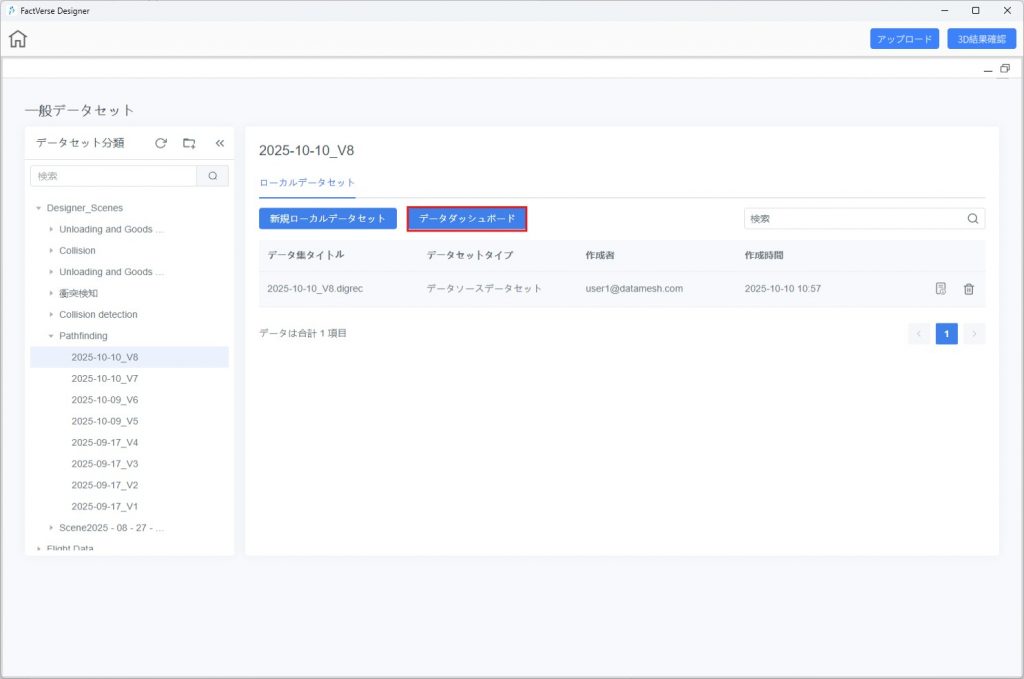
c) ダッシュボードキャンバスに設定済みの経路分析表が表示されるので、経路を確認したいデジタルツインをチェックします。
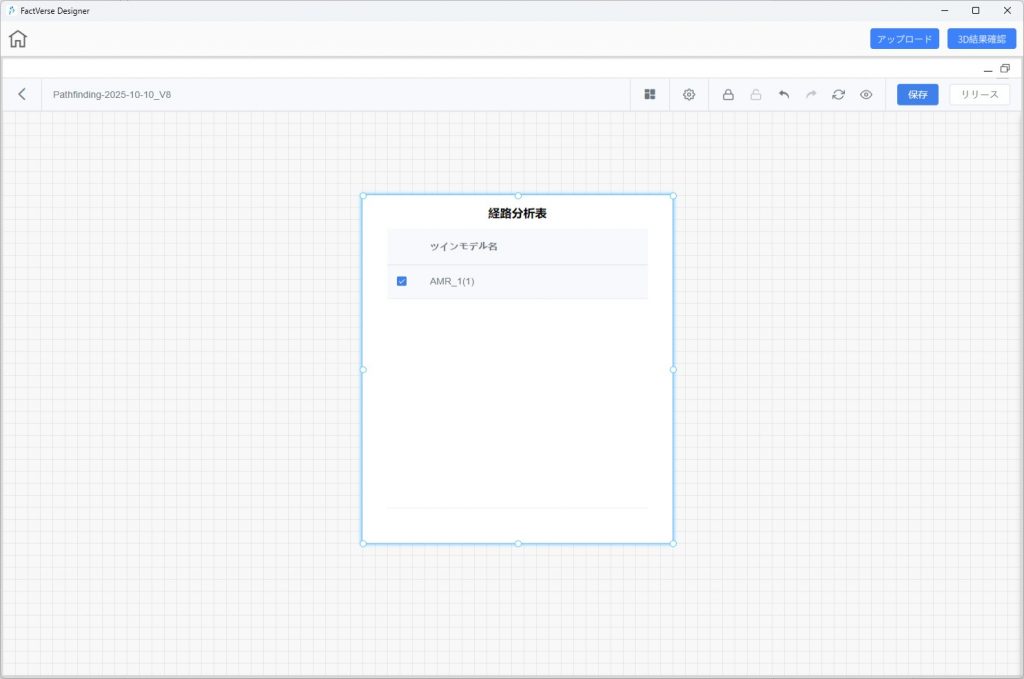
d) 【3D 結果表示】をクリックすると、Designer が対応するシナリオを読み込み、選択したデジタルツインの走行経路を重ねて表示します。
e) シナリオを正しく確認するために、データダッシュボードのウィンドウを最小化するか画面の一方に移動し、3D シナリオ内の経路表示を全体的に確認できるようにします。
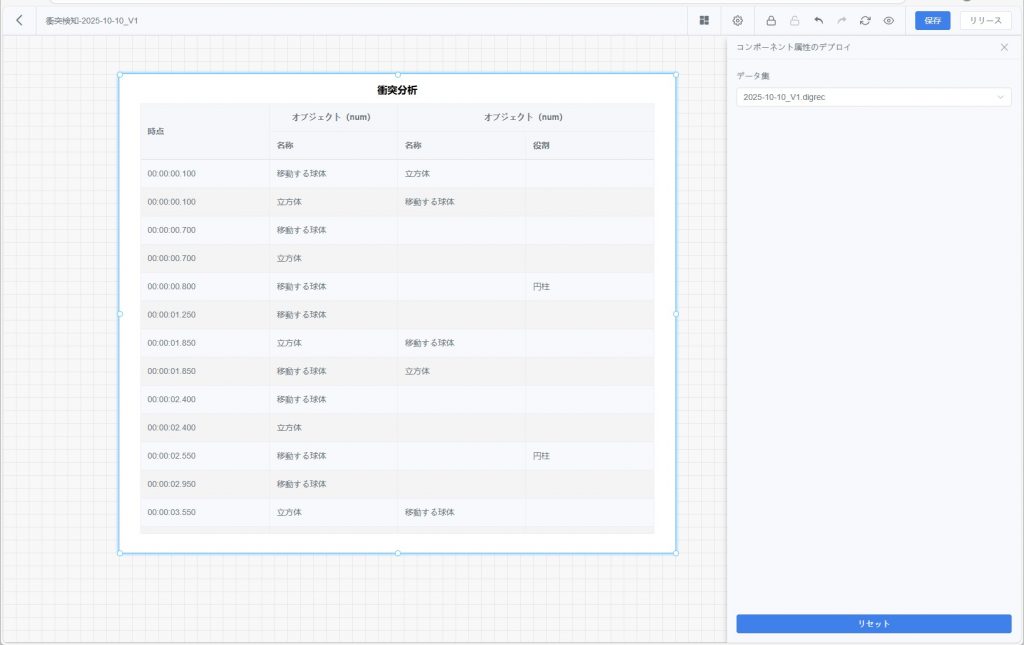
衝突検知
衝突検知コンポーネントは、シミュレーションレビューで表示される【衝突統計】の明細表をダッシュボードに設定するものです。
衝突イベントの詳細はリスト形式でカードに表示され、すべての衝突結果を確認できます。
操作手順
- DFS で衝突検知コンポーネントを設定:【コンポーネントメニュー】から【衝突検知】を選択し、ダッシュボードキャンバスに追加します。
- コンポーネントをダブルクリックし、右側の設定欄でバインドするデータセットを選択します(通常はシナリオシミュレーションレビューで生成されたデータセット)。
- 【更新】をクリックして効果を確認し、【保存】をクリックしてダッシュボード設定を保存します。
グラフ系コンポーネント
グラフ系コンポーネントは、データセットのフィールドを多様な可視化方法で表示し、対話的な分析や比較をサポートします。
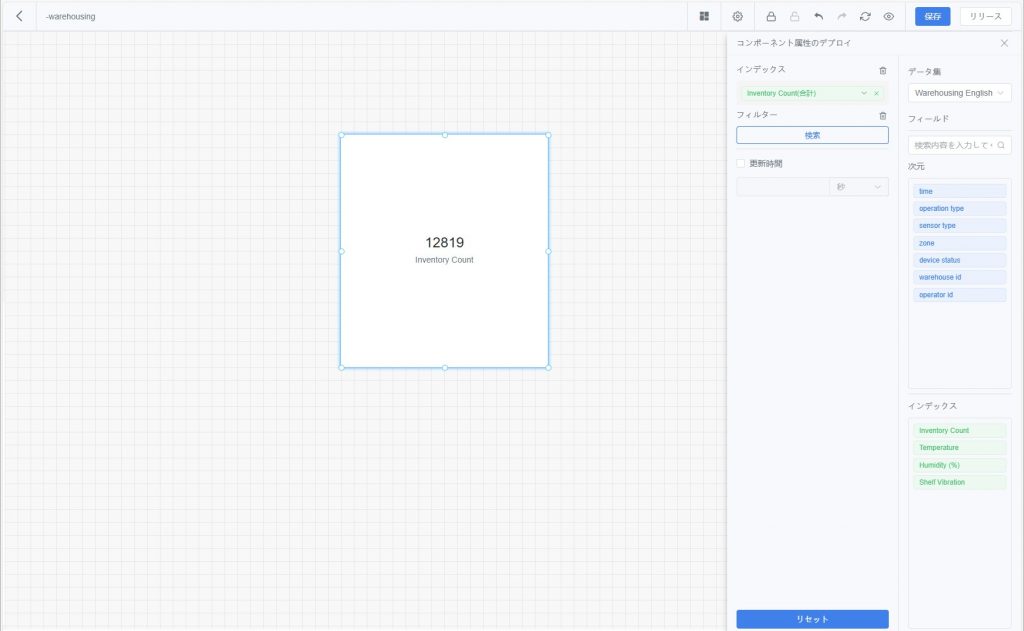
- 統計指標:特定の指標フィールドの集計結果(合計、平均、最大値、最小値など)を直接表示し、重要な数値を迅速に把握可能。
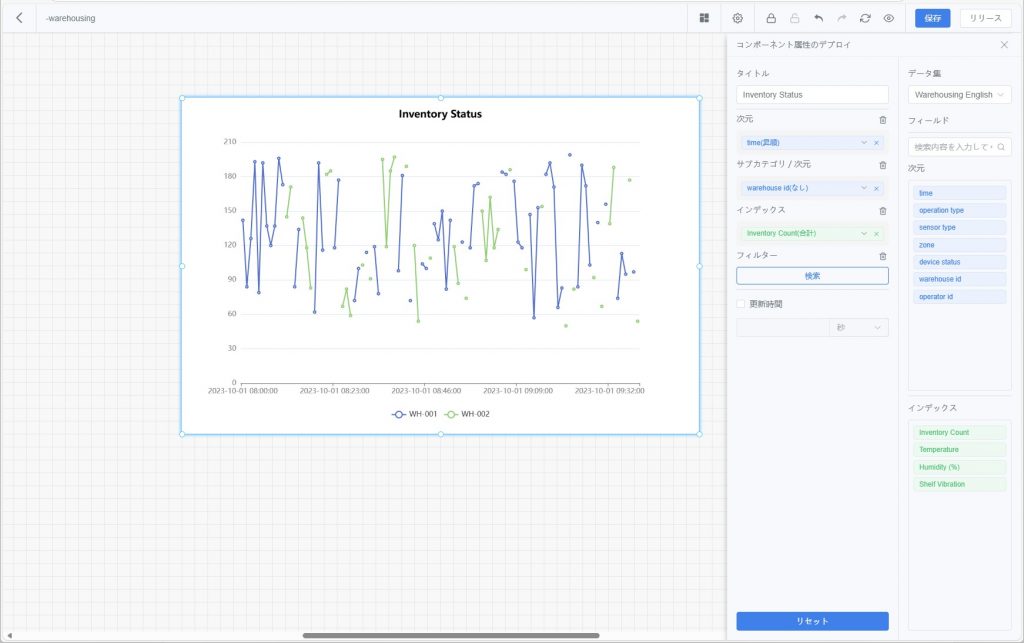
- 折れ線グラフ:指標が時間または他のディメンションに従って変化する傾向を表示し、データの変動や比較を直感的に反映。同じ折れ線グラフで複数カテゴリを比較するために「サブカテゴリ/ディメンション」を設定可能。例:異なる設備の温度曲線。
- 散布図:2 つ以上の指標間の分布と相関を表示、関連性分析に適する。
- 円グラフ:カテゴリごとの比率を表示、構成比分析に適する。
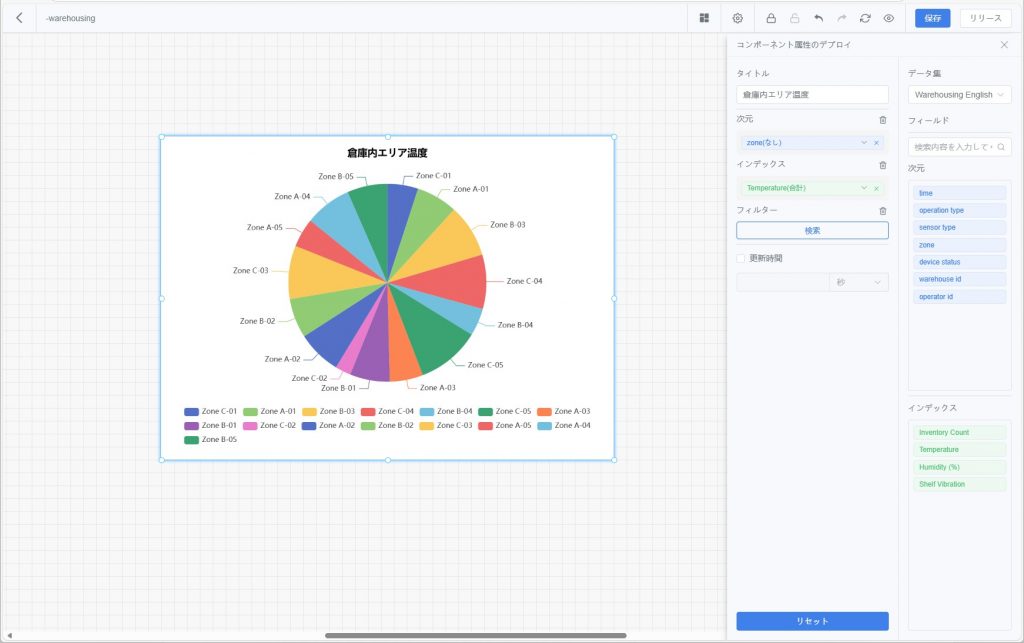
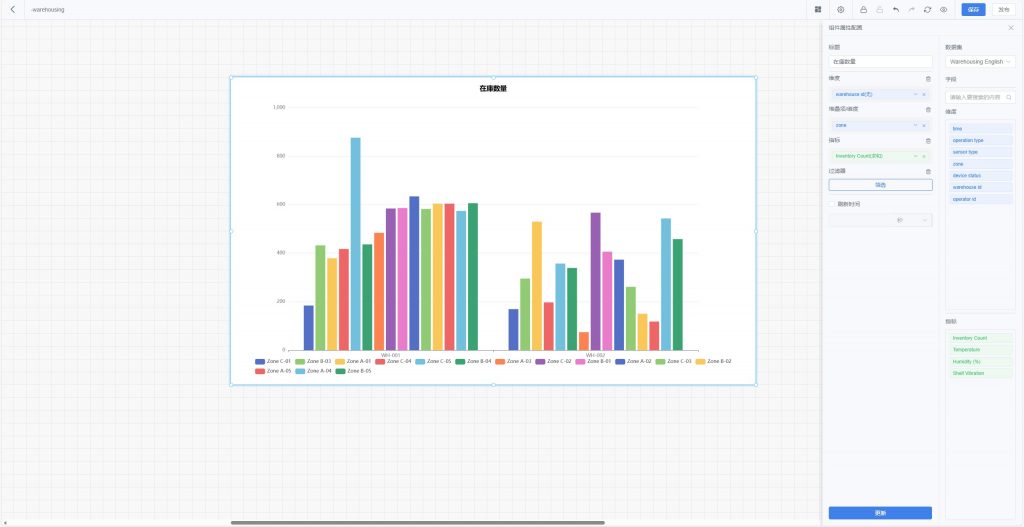
- 棒グラフ:カテゴリごとの数値比較を表示、分類比較分析に適する。
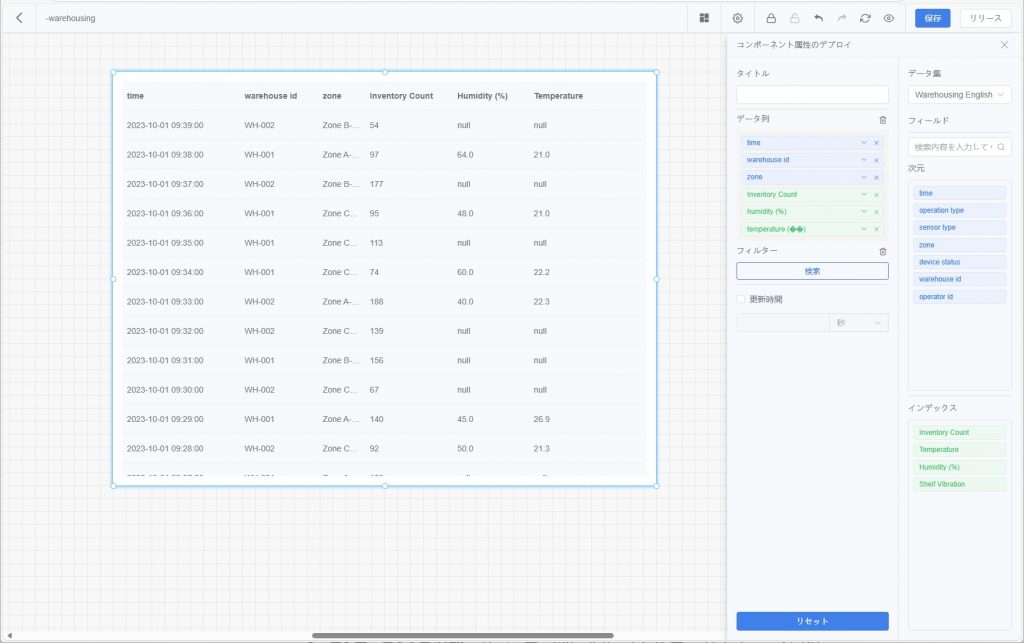
- 明細表:ディメンションと指標データを表形式で列挙し、複数列設定やソートに対応。詳細確認に適する。データ列に表示するディメンションや指標を設定可能。
異なる種類のグラフはいずれも、以下の「共通設定手順」に従って構成します。
共通設定手順
1. コンポーネントを追加:ダッシュボードツールバーで【コンポーネントメニュー】をクリックし、目的のグラフタイプを選択してキャンバスに追加します。
2. 属性設定パネルを開く:コンポーネントカードをダブルクリックすると、右側に属性設定パネルが表示されます。
3. タイトルを設定:コンポーネントのタイトルを入力し、識別・管理しやすくします。
4. データセットを選択:利用可能なデータセットから 1 つを選択し、グラフのデータソースとします。
5. ディメンションと指標を設定:
a) フィールドリストからディメンション/指標を対応エリアにドラッグします。
b) ディメンションに対して並び順(昇順、降順、またはデフォルト)を設定できます。
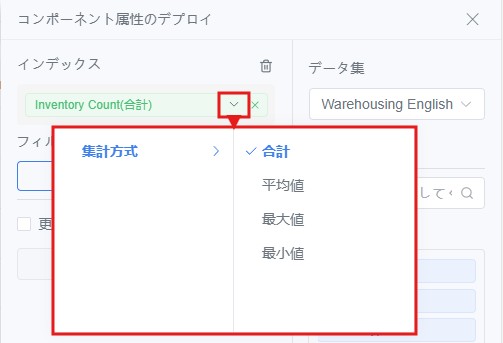
6. 指標の集計方法を設定(合計、平均、最大値、最小値など)。
7. フィルターを追加(任意):時間、デバイス ID などの条件でデータを絞り込みます。
8. 更新間隔を設定(任意):秒単位でコンポーネントデータの更新頻度を設定できます。
9. 更新して保存:【更新】をクリックして効果を確認し、問題なければ【保存】をクリックします。
テキストと画像
テキストコンポーネント
データダッシュボードに説明用テキスト、タイトル、備考を追加するために使用され、グラフ内容の解説や業務背景の補足を行います。
- 任意のテキスト内容を入力可能
- 内容を選択するとテキスト編集ツールバーが表示され、文字サイズ・色・背景色などを編集可能
- ダッシュボードレイアウトに合わせてコンポーネントの位置やサイズを調整可能
画像コンポーネント
静的な画像(企業ロゴ、フローチャート、概念図など)をダッシュボードに表示するために使用し、可読性と視覚的な美しさを向上させます。

データ探索
データ探索は、DFS プラットフォームにおいて データ分析、特徴抽出、異常検知 を行うための中核機能です。ビジュアルベースのタスクオーケストレーションにより、ユーザーはデータ処理フローの構築、探索手法やアラートルールの設定、および探索フローのテンプレート化(テンプレートとしての公開)を行うことができ、同一系統のデータに対する自動分析・モニタリングを実現します。
探索タスクの実行後、システムは新しい探索データセットを生成し、追加の分析・検証、ダッシュボードでの可視化、あるいは業務判断に活用できます。アラートルールが設定されている場合、テンプレート実行中にシステムが自動的に異常を検知し、アラートイベントを生成することで、継続的に運用可能なモニタリングサイクルを形成します。
主要概念
- データ探索データセット:探索タスクの実行後に生成される結果データセットで、通常は処理ロジックと特徴変数が含まれる。
- アラートルール:データ異常を検知するためのトリガー条件を定義します。閾値判定、トレンド変化、複数条件の組み合わせなどを設定できます。
アラートルールを有効にすると、テンプレート実行中にシステムがデータ状態を自動監視し、事前に設定した条件を満たした時点でアラートイベントを生成し、ユーザーに対して迅速にリスクを通知します。
ヒント: アラートルールを設定していない場合、システムはデータ探索処理のみを実行し、異常検知やアラート判定は行いません。
- データ探索テンプレート:探索ロジックや処理ルールを事前に定義したもので、再利用可能で探索効率を高める。
- 同源同構データ:同一のデータソースまたは取得チャネル(例:同一デバイス、センサー、インターフェース、統合システム、あるいは同一ツインモデルから生成されたシミュレーション記録)から得られ、データ構造・フィールド形式・意味定義が一致しているデータを指します。
データ探索編集パネル
データ探索編集パネルは、データ処理フローを可視的に構築できる編集インターフェースで、ツールバー、ノードパネル、キャンバスエリア、補助的なインタラクション機能 で構成されています。
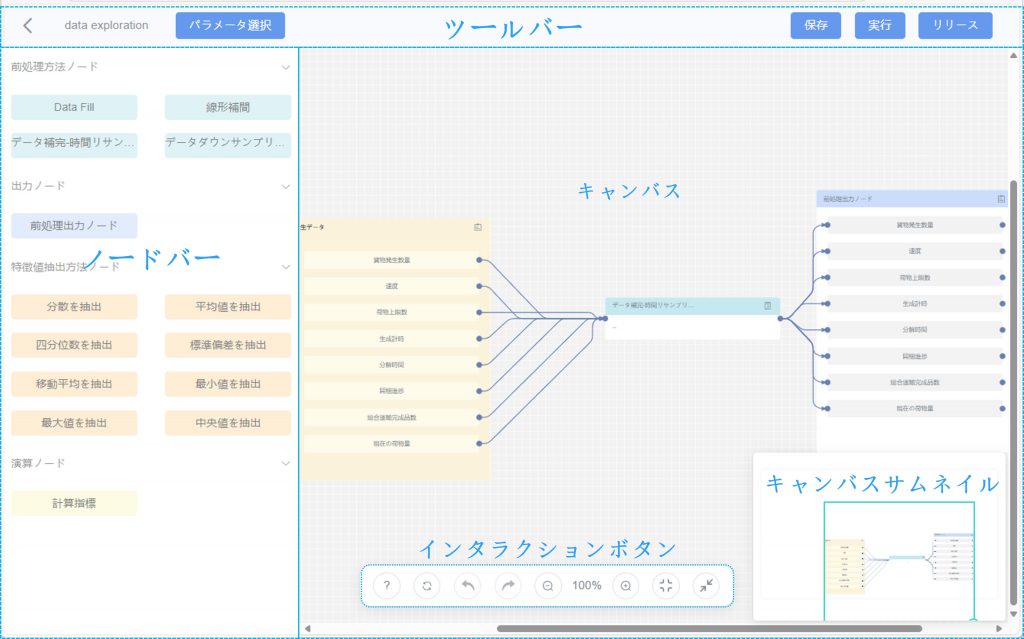
ツールバー
![]()
- パラメータ選択:パラメータタグやデータセットタグから元データを選択するために使用。
- 実行:現在のタスクを実行し、処理後の結果を生成。
- 保存:現在のタスク設定を保存。
- リリース:データ探索テンプレートを公開すると、同源・同構型データに対して自動で分析とアラート判定が実行されます。
ノードバー
「ノードバー」には多様なデータ処理、分析、モデル計算、出力ノードが提供されており、ユーザーは業務要件や分析ロジックに応じて柔軟に構成可能。以下は各種ノードの詳細説明と適用シーン、使用方法。
- 前処理方法ノード:前処理ノードは元データを初期処理し、その後の分析を容易にする。
- 線形補間:
- 機能:欠損点前後の変化を線形と仮定し、欠損値を推定。既知データ点を直線で結び空白を埋める。
- 適用シーン:時系列データに少量の欠損値がある場合、データの連続性を維持。
- データダウンサンプリング:
- 機能:高頻度データを低頻度データに変換(例:ミリ秒単位データを 1 秒ごとに集計)。
- 適用シーン:過剰に頻繁なデータを簡素化して分析。
- データ補完–時間リサンプリング:
- 機能:低頻度データを高頻度にリサンプリングし、高・低頻度データを同時に分析可能にする。
- 適用シーン:高頻度と低頻度の混在データを統一する必要がある場合。
- カスタム前処理方法:
- 機能:ユーザーが特定要件に応じた前処理ロジックを作成可能。
- 適用シーン:標準処理で対応できない場合の拡張性を提供。
- 特徴量抽出ノード:データから重要な統計特徴を抽出し、後続のモデリング・分析に使用。
- 最大値抽出:データ中の最大値を抽出する
- 四分位数抽出:データを並べ替えて4等分し、3つの分割点(25%、50%、75%)の値を抽出する。
- 標準偏差抽出:データの標準偏差を計算し、データの変動程度を反映する。
- 中央値抽出:データセットの中央値(50%分位点)を抽出する。
- 平均値抽出:データの平均値を抽出する。
- 分散抽出:データセットの分散を計算し、データのばらつきを反映する。
- 最小値抽出:データ中の最小値を抽出する。
- カスタム特徴量抽出方法:特定の要件に基づき、独自の特徴抽出ルールを記述する。
- 線形補間:
- アラートルールノード:データに対するアラート発生条件を定義するためのノードです。
- ルールアラート: しきい値判定、範囲チェック、複数条件の組み合わせなど、事前に設定した判定ロジックに基づきデータを継続的に監視します。データが設定したアラート条件を満たし、かつ指定したロジック(例:「すべて満たす」「いずれかを満たす」)に一致した場合、システムはアラートを自動的に発報し、対応するアラート情報を生成します。
- 演算ノード:データ処理の過程で数値演算を行うノード。計算モデルの構築や新しいデータ指標の生成に用いられる。
- 出力ノード:処理結果を他のモジュールに出力または伝達するためのノード
- 前処理出力ノード:前処理済みデータを出力し、その後の分析で利用可能にする。
キャンバス(タスク編成エリア)
このエリアではデータ探索タスクの設定を行うことができます。主に以下の機能をサポートします:
- ノードの追加:左側のノードバーからノードをキャンバスにドラッグして、タスクの基本フレームを作成できます。
- ノードの接続:ノード間に接続線(矢印)をドラッグしてデータフローの方向を定義します。矢印はデータがあるノードから別のノードに流れる順序を表し、タスクが正しい順序で実行されることを保証します。
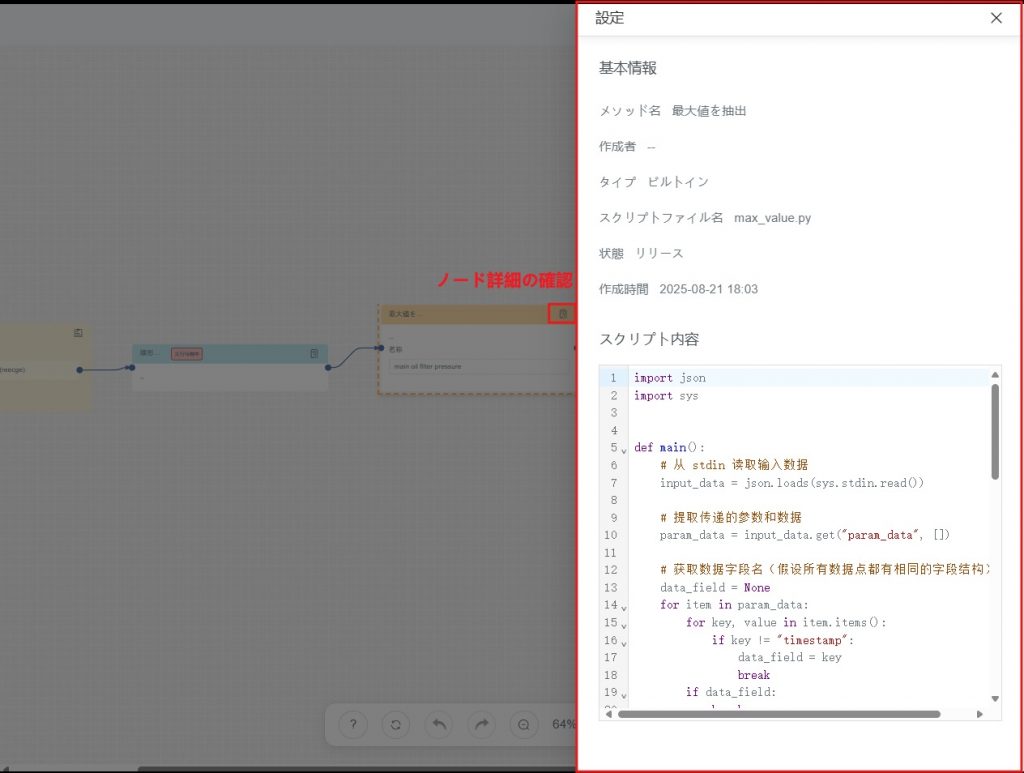
- ノード詳細の確認:
- 基本情報:処理方法の名称、タイプ、作成者、ステータスなどの情報。
- 関連コード:ノードに関連付けられたコードやスクリプト。
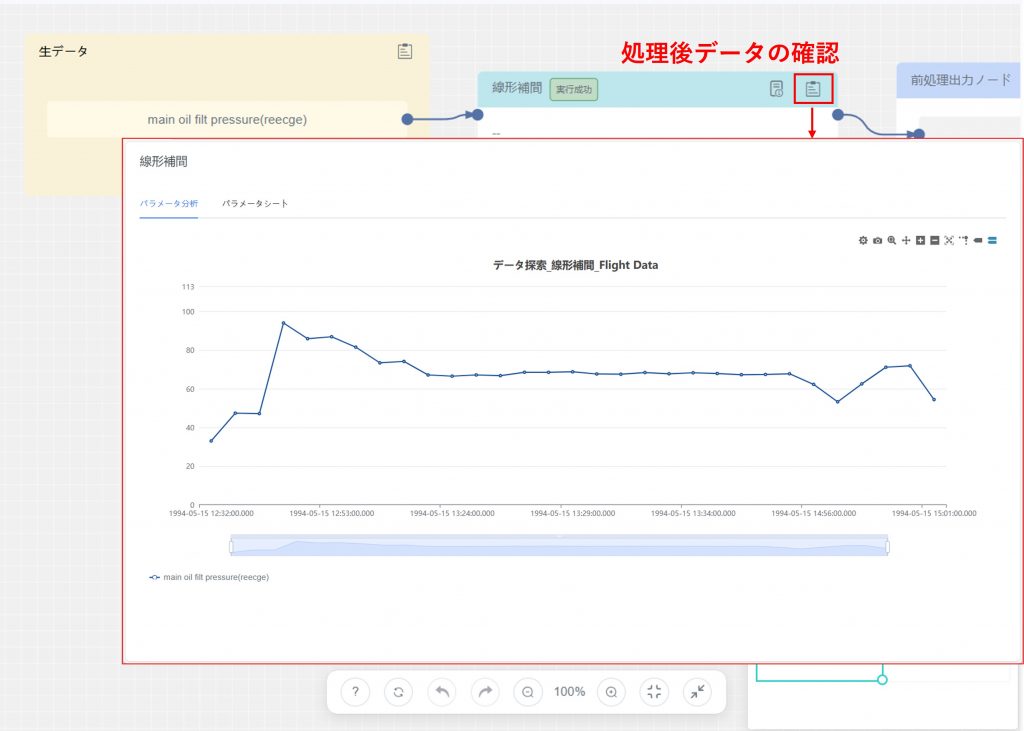
- 処理後データの確認:タスク実行後、キャンバス上で各ノードの処理結果データを確認でき、タスク実行結果の分析に役立ちます。
インタラクションボタン

- ヘルプ:ショートカットキーを確認。
- キャンバスをクリア:キャンバス上のすべてのノードと接続を削除し、初期の空白状態に戻す。
- 取り消し:直前の操作を取り消し、キャンバスを前の状態に戻す。
- やり直し:取り消した操作をやり直し、取り消し前の状態に戻す。
- 縮小:キャンバスビューを縮小し、より広い範囲を表示して全体を把握しやすくする。
- 拡大:キャンバスビューを拡大し、内容をより詳細に表示して特定部分に集中できるようにする。
- リセット:キャンバスビューをデフォルト設定に戻し、サイズや表示倍率を初期状態に戻す。
- フィット:キャンバス内の内容表示を自動調整し、現在のウィンドウまたは表示エリアに適合させる。
キャンバスサムネイル
キャンバス右下のサムネイルは、複雑なキャンバス内での位置決めや表示領域の調整を容易にするためのクイックナビゲーションおよびビュー調整機能を提供します:
ビューの拡大縮小:緑色のビューポート右下の丸いハンドルをドラッグして視窗を拡大・縮小し、キャンバス内の表示範囲を調整します。
ビューを移動:緑色のビューポート自体をドラッグするか、またはビューポート外の空白部分をクリックすると、ビューの位置を変更でき、キャンバスに表示する具体的な内容領域を調整できます。
データ探索の設定
ドラッグ&ドロップやノードの接続によって、データ処理方法と元データ間の関係を設定し、ワークフロー形式でのデータ探索設定を実現します。
- データ探索編集パネルを開く:
- 自動オープン:新しいデータ探索を作成すると、システムが自動的に「データ探索編集パネル」を開きます。
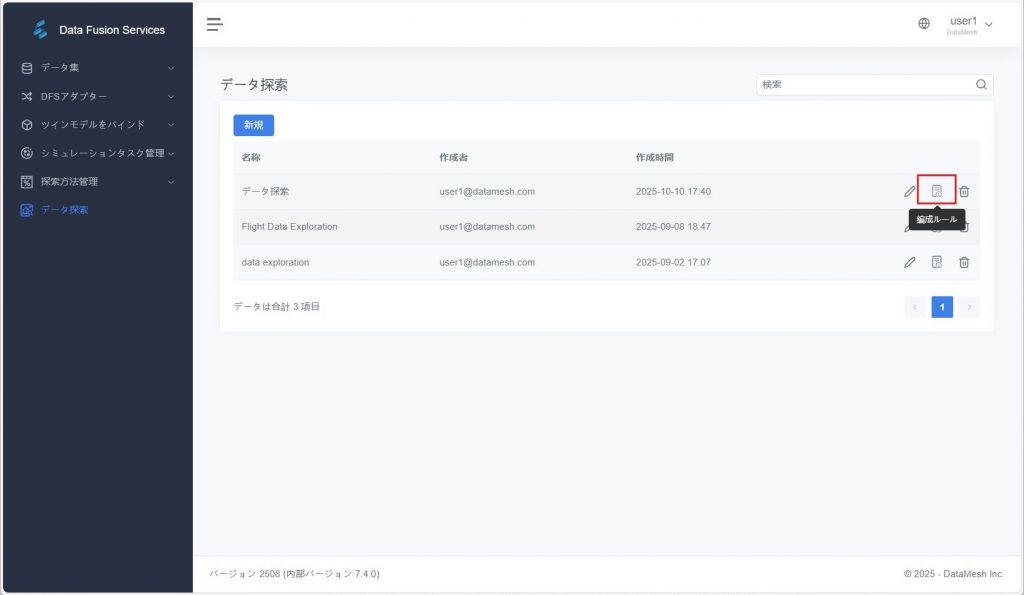
- 手動オープン:データ探索ページで、編集したいデータ探索を選択し、探索名または【編成ルール】ボタンをクリックして「データ探索編集パネル」を開きます。
- 元データを選択:
a) ツールバーの【パラメータ選択】ボタンをクリックし、データ選択ウィンドウを開きます。
b) ポップアップウィンドウで以下の方法により必要なデータを絞り込みます:
- パラメータ:データセットから必要なパラメータを選択。
- パラメータルール:パラメータの値範囲を設定し、さらに絞り込み、目的データを素早く特定。
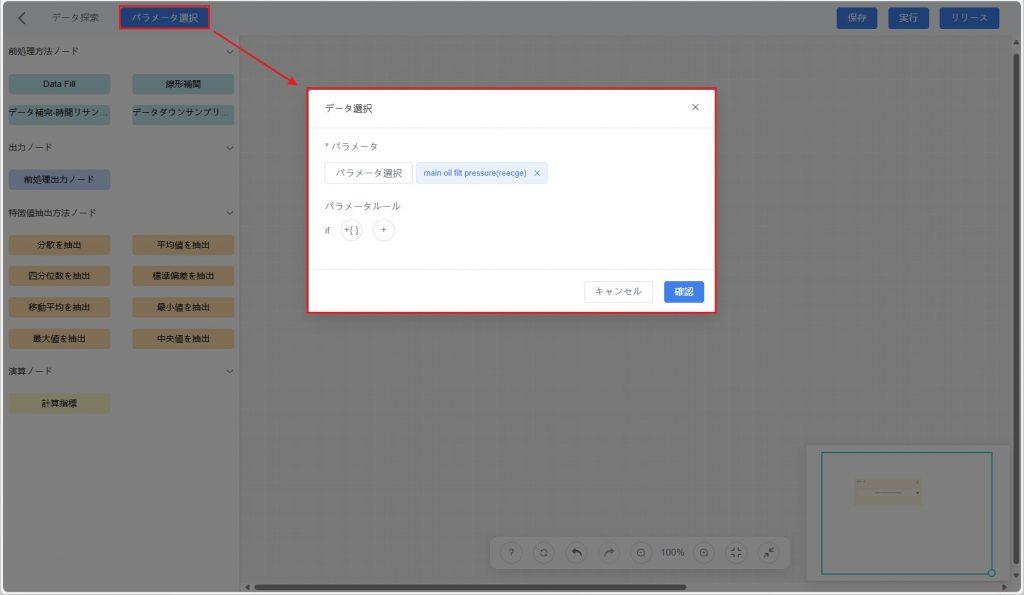
c) 【確認】をクリックすると、キャンバス上に「元データ」ノードが追加されます。
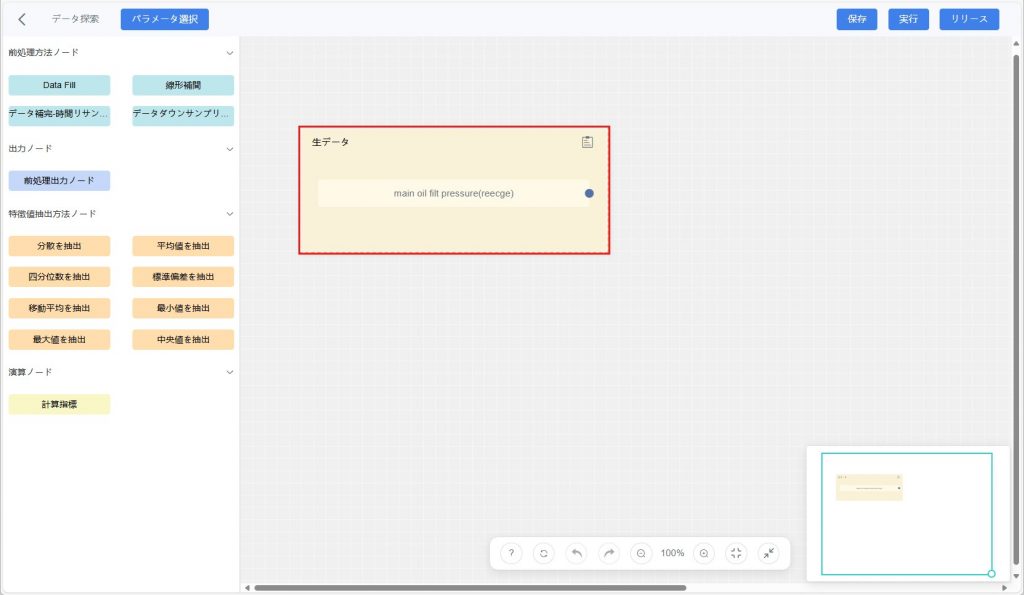
- データ処理方法を選択
a) 左側のノードバーから必要なノードをキャンバスにドラッグします。
b) あるノードの出力端から別のノードの入力端へ接続します。矢印はデータ処理の順序を表します。
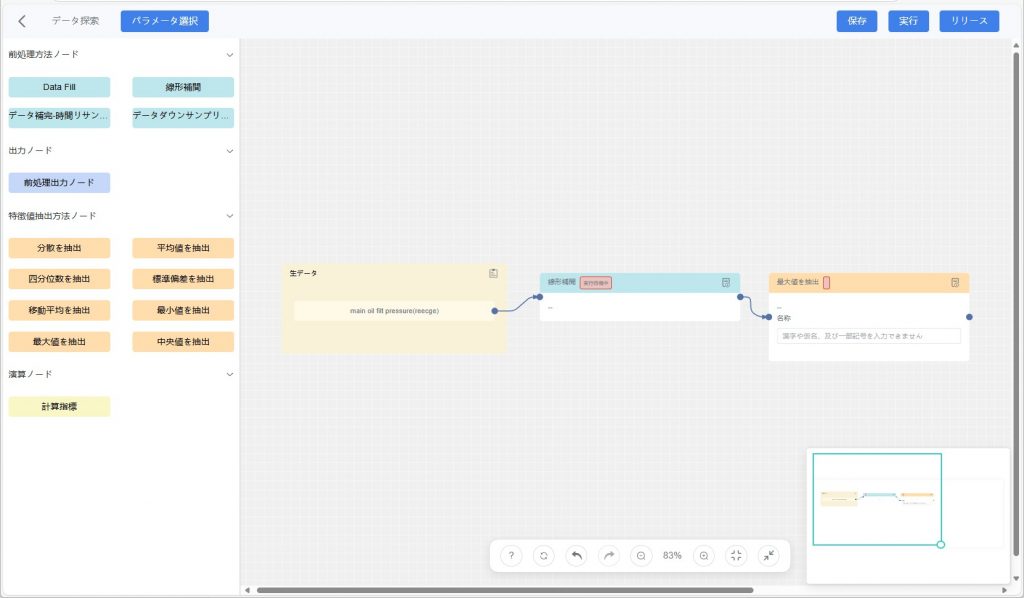
- タスク設定の保存:【保存】をクリックし、現在のタスク設定を保存します。
データ探索フロー
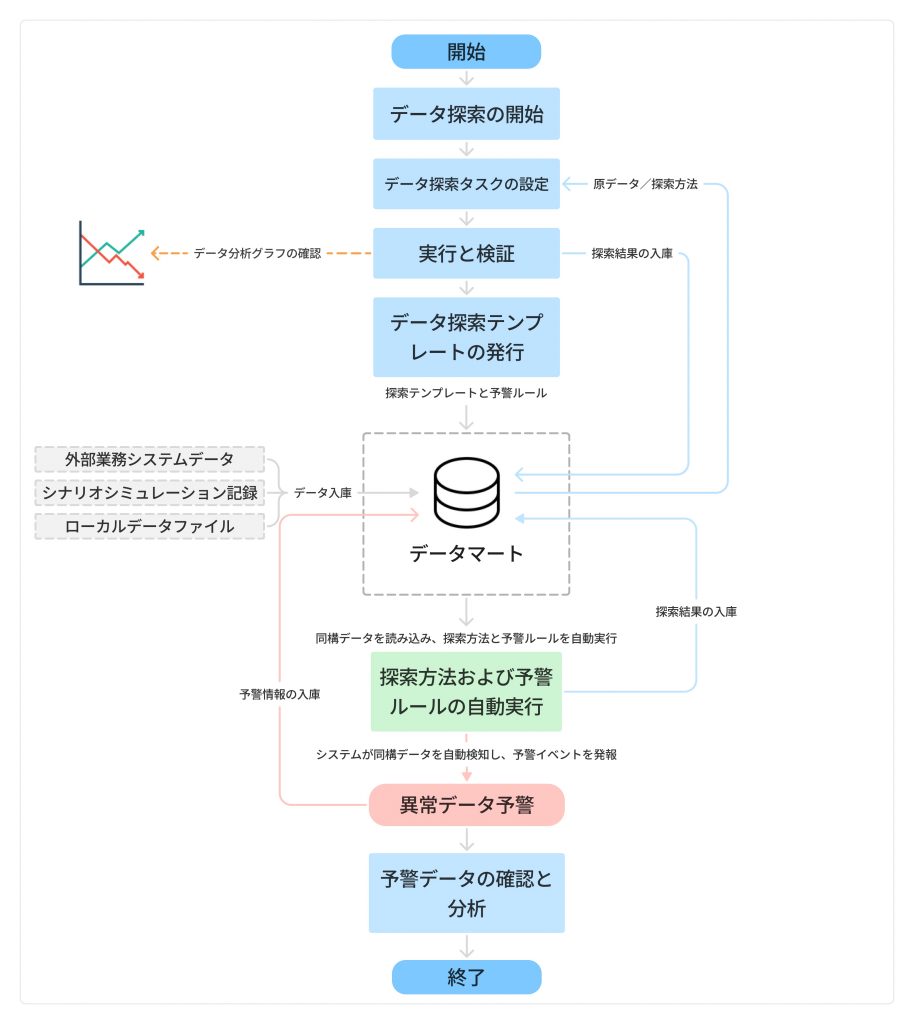
上図は、データ探索タスクが「構成 → 実行 → テンプレート公開 → 自動実行 → 結果保存」に至るまでの一連の処理フローを示しています。本フローではアラートルールの設定もサポートしており、アラートを有効化していない場合は、システムはデータ処理のみを行い、異常判定は実施しません。
データ探索フローは、以下のような多様なデータソースに対応しています:
- 外部業務システムからプラットフォームに取り込まれたデータ
- FactVerse Designer で生成・アップロードされたシミュレーション記録
- ユーザーが汎用データセットとして手動アップロードした .csv ファイル
探索テンプレートを公開すると、プラットフォームは後続で取り込まれる同源同構データに対して自動的に探索ロジックを実行します。また、設定したルール条件を満たした場合はアラートが自動的に発報され、アラート詳細の確認や発生要因の追跡(トレース)も可能になります。
データ探索の開始
データ探索タスクは、以下の 2 つの方法で開始できます:
方法 1:[データ探索]ページから新規タスクを作成する
操作手順
- データ探索ページで【新規】をクリックする。
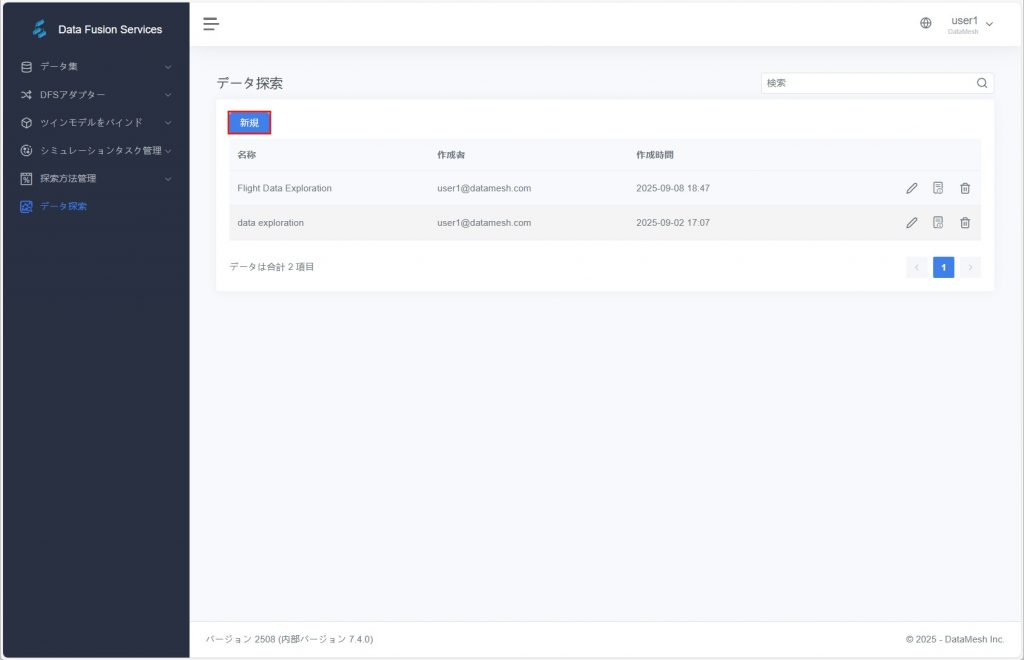
- ポップアップウィンドウでタスク情報を入力。
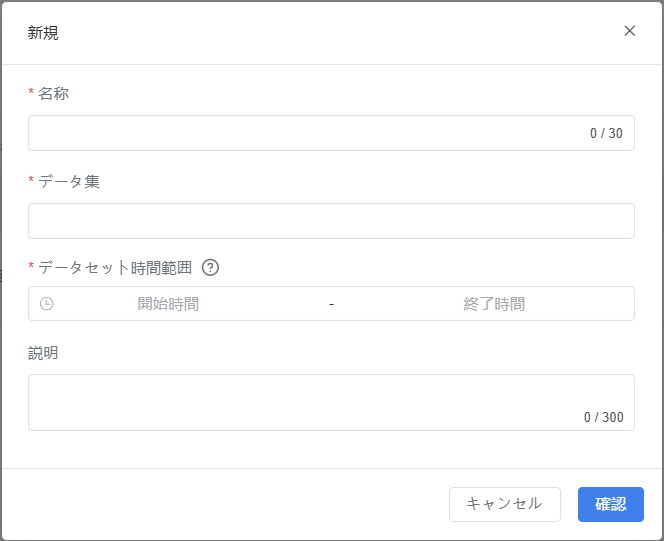
- 名称(必須):データ探索タスクの名称を入力します。
- データ集(必須):分析対象のデータセットを選択します。
- データセット時間範囲(必須):開始時間と終了時間を指定して分析範囲を選択します。
- 説明(任意):タスクの用途や背景を補足説明します。
- 【確認】をクリックし、データ探索編集パネルに進みタスク設定を行います。
方法 2:汎用データセットページから直接発起する
操作手順
- 一般データセットページで対象データセットを選択し、データセット名または詳細ボタンをクリックしてデータ表示ページに入ります。
- 「データ表」タブで【データ探索開始】ボタンをクリックします。
- ポップアップウィンドウでタスク情報を入力:
- 名称(必須):探索タスクの名称を入力します。
- 説明(任意):タスクの背景や目的を補足します。
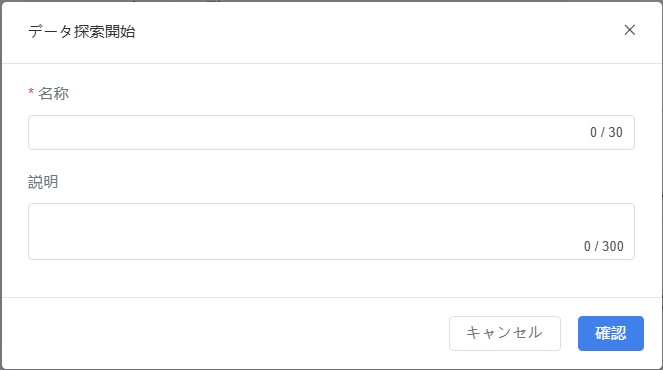
- 【確認】をクリックし、データ探索編集パネルに進みタスク設定を行います。
データ探索タスクの設定
タスク設定用の編集キャンバスでは、ノードのドラッグ&ドロップおよびデータフローの接続によって、データ処理フローを視覚的に構築できます。また、必要に応じて予警ルールの設定も行えます。
操作手順
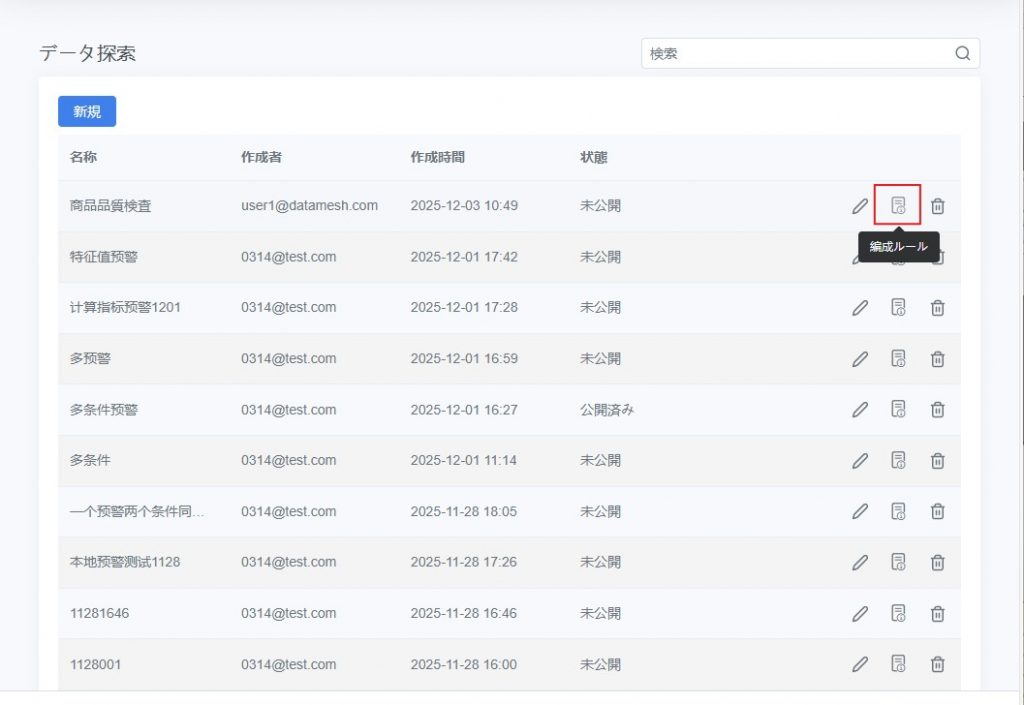
- 編集パネルを開く
- データ探索の新規作成」を実行すると、自動的に編集パネルが開きます。
- 既存タスクの場合は、データ探索一覧から対象タスク名、または [ルール編成] をクリックして編集パネルに入ります。
- 元データの選択
a)[パラメータ選択] をクリックし、データ選択ウィンドウを開きます。
b) 表示されたウィンドウで、以下の方法を用いて必要なデータを絞り込みます:
- パラメータ:データセットから必要なパラメータを選択。
- パラメータルール:パラメータの値範囲を設定し、さらに絞り込み、目的データを素早く特定。
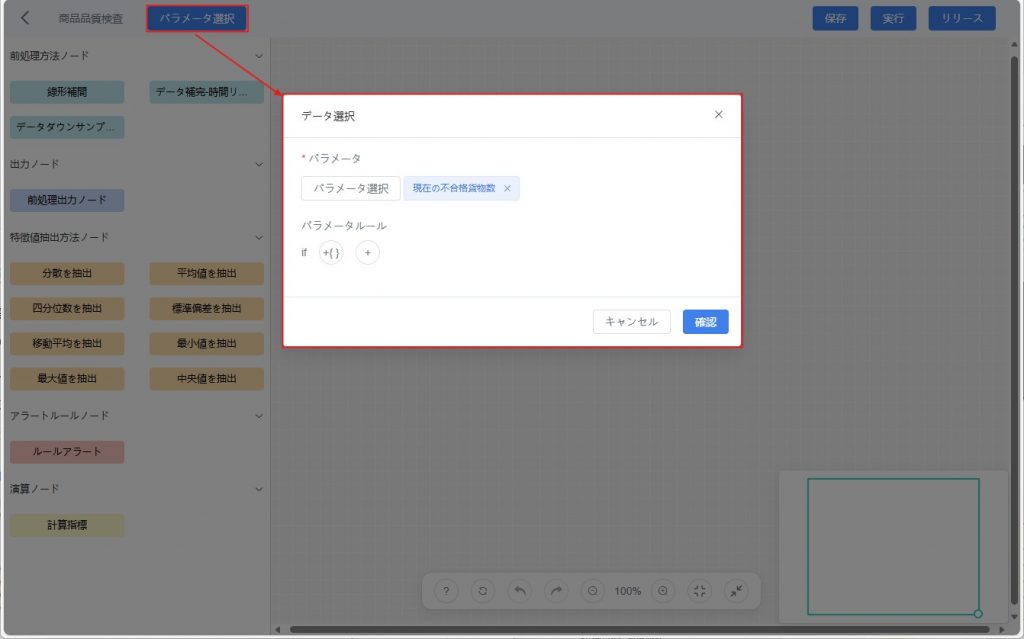
c)【確認】をクリックすると、キャンバス上に「元データ」ノードが追加されます。
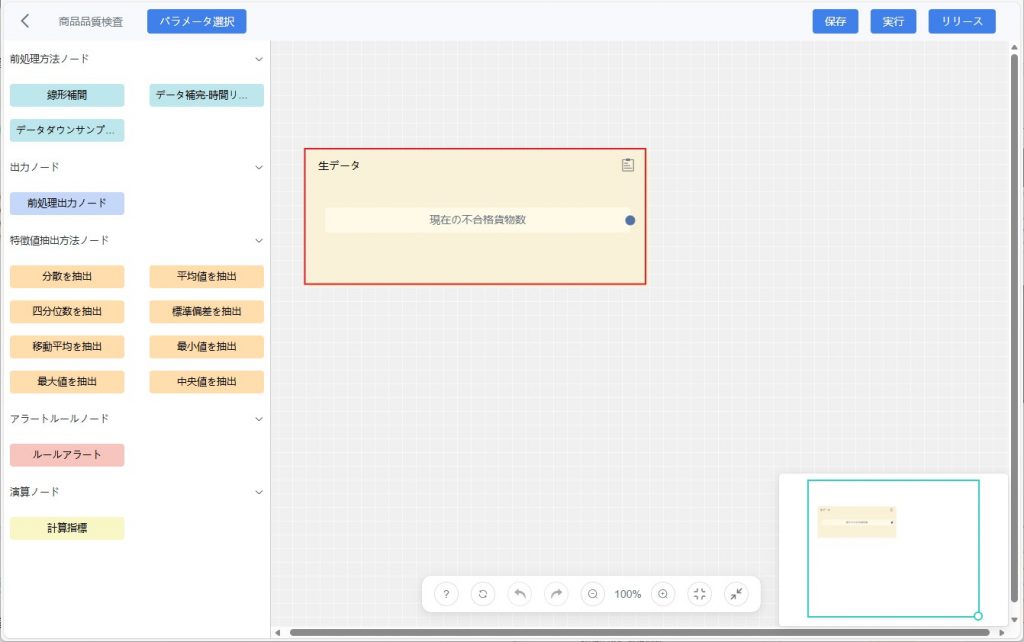
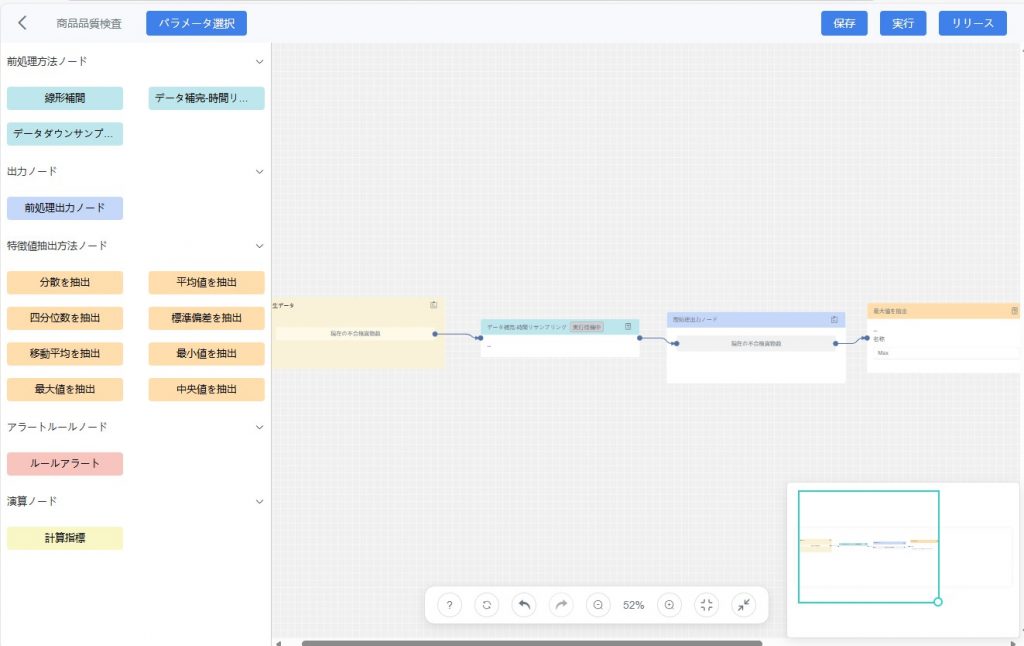
- データ処理フローの構築
- 処理ノードをキャンバス上へドラッグし、ラインで接続することでデータ処理ロジックを構築します
- 特定のアルゴリズムを使用する場合は、事前に「探索手法管理」モジュールでカスタム手法を作成しておくことができます
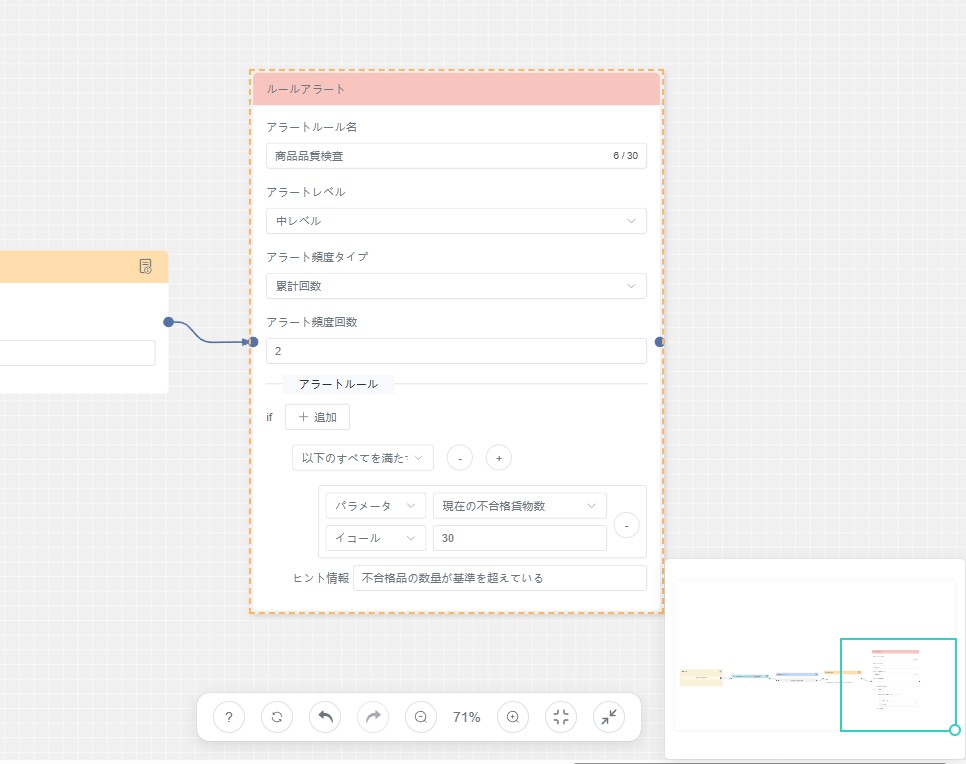
- アラートルールの設定(任意)
a) キャンバスに 「アラートルール」ノード をドラッグし、上流ノードと接続します。
b) ルール条件を設定します(詳細は次節「アラートルール設定ガイド」を参照)。
- 設定の保存:【保存】 をクリックし、現在のデータ探索設定を保存します。
アラートルール設定ガイド
データ探索フローでは、重要なパラメータ・特徴量・算出指標に対してアラートルールを設定できます。設定されたルールに基づき、システムは異常値を自動検知し、アラート記録を生成します。
対応機能:
- 複数条件の組み合わせ判定:複数のルール条件を追加可能
- ロジック方式の切り替え:「すべて満たす」/「いずれか満たす」
- 柔軟なトリガーメカニズム:多様な発火頻度設定に対応
- アラートメッセージのカスタマイズ:異常発生時の案内文を自由に設定可能
設定項目の説明
設定項目 | 説明 |
アラートルール名 | 必須。ルールを識別するための名称。 |
アラートレベル | 「高 / 中 / 低」から選択可能。 |
アラート頻度タイプ | アラートの発火条件と頻度を設定します:
|
ロジック方式 | 複数条件を設定した場合の評価方法:
|
条件タイプ | アラート判定対象となる項目:
|
演算子 | 比較方式。>、≥、<、≤、=、≠、含む、含まない。 |
閾値 | 条件と組み合わせて使用する比較値。例:温度 > 70°C |
メッセージ | アラート発火時に表示する案内文。簡潔で具体的な内容を推奨(例:「温度が上限を超過しました。設備を確認してください。」) |
実行と検証
タスクの設定が完了したら、以下の操作により、探索フローの正確性とデータ処理結果を確認できます:
- タスクの実行:【実行】ボタンをキャンバス右上でクリックすると、システムはキャンバスに定義されたデータ処理ロジックに従ってノード処理を実行し、データ分析結果を生成します。
実行過程には、データクリーニング、特徴抽出、モデル計算などの操作が含まれる場合があります。キャンバスで設定されたノードに依存して処理されます。実行後、業務ニーズと処理ロジックに基づいたデータ結果が得られ、その結果は自動的に汎用データセットに保存され、後続の閲覧や分析に利用できます。
- データ検証:データ処理ノード上の閲覧ボタンをクリックすると、そのノードの出力結果を表やグラフで表示します。
- データのトレンド、パターン、異常値などを確認し、データが期待に沿っているかを分析します。
- グラフや表の結果を比較し、期待される計算結果や分析結果と一致しているか確認します。
- 元データ、外部データソース、または既知の基準と比較し、データ処理の正確性を検証します。
- データ処理の最適化:もし処理結果に問題がある場合、分析者はノード設定を調整したり、タスクを再実行することで修正や最適化を行うことができます。
データ探索テンプレートの公開
タスク設定が問題なく完了したら、【公開】をクリックし、現在の探索フローを再利用可能なテンプレートとして登録できます。
- テンプレートを公開すると、以降インポートされる同源同構データに対し、システムが自動的に探索ロジックを適用します
- ルールアラートが設定されている場合、異常が検知され次第、自動的にアラートを発報し、システムに記録されます
アラート情報の確認と分析
発報されたアラートについては、システム上で詳細情報を確認でき、さらに発生元となった探索フローへ遡って原因分析を行うことができます。
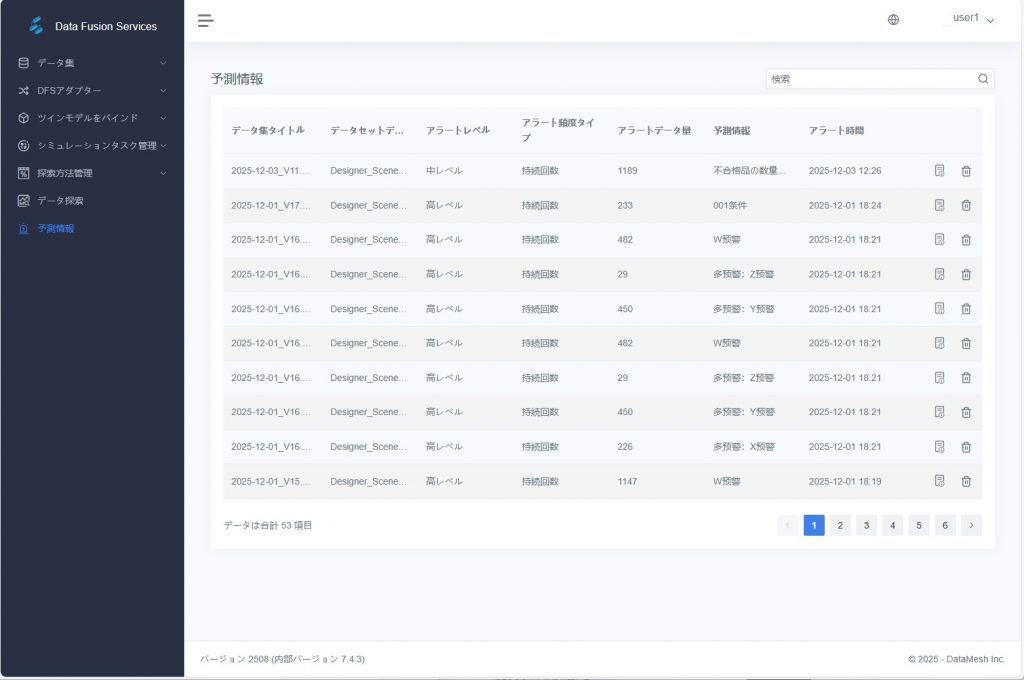
操作手順
- アラート記録の検索:「アラート情報」ページにて、フィルタ条件を利用し目的のアラートを絞り込みます。
- 詳細確認:対象行をクリックするとアラート詳細ページが開き、以下の情報を確認できます:
- アラート発生時刻、レベル、メッセージなどの基本情報
- 使用されたアラートルールの設定内容および発動ロジック
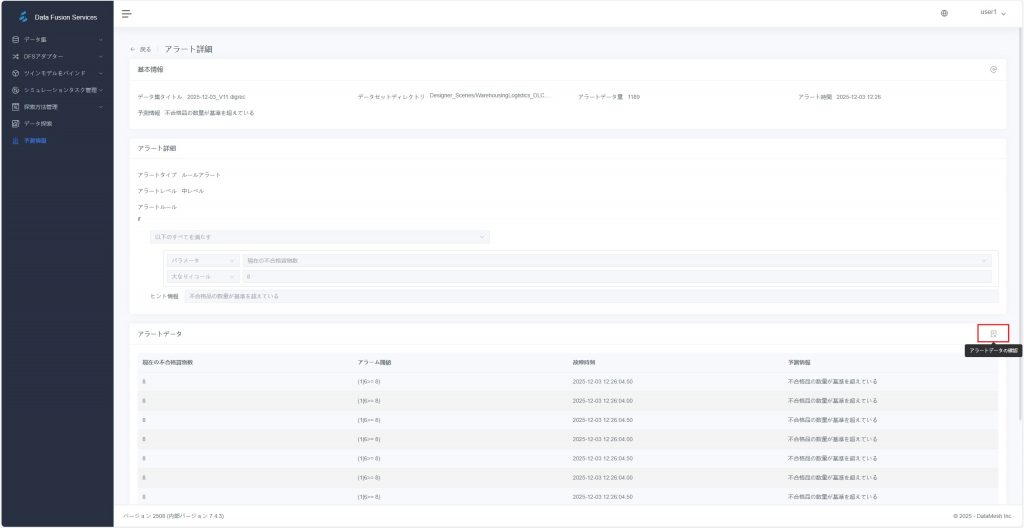
- トレース分析:
a) 右下の【アラートデータ確認】アイコン![]() をクリックし、アラート発生時のデータ明細を確認します。
をクリックし、アラート発生時のデータ明細を確認します。
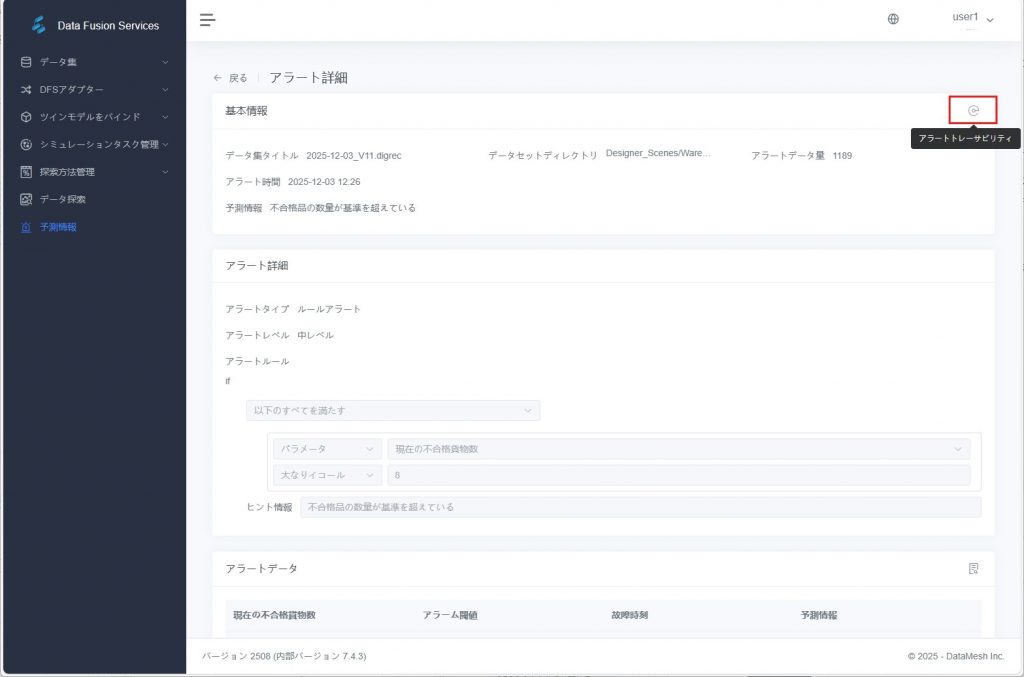
b) 右上の【アラートトレース】ボタン![]() をクリックすると、関連するデータ探索タスクの編集パネルへ遷移します。
をクリックすると、関連するデータ探索タスクの編集パネルへ遷移します。
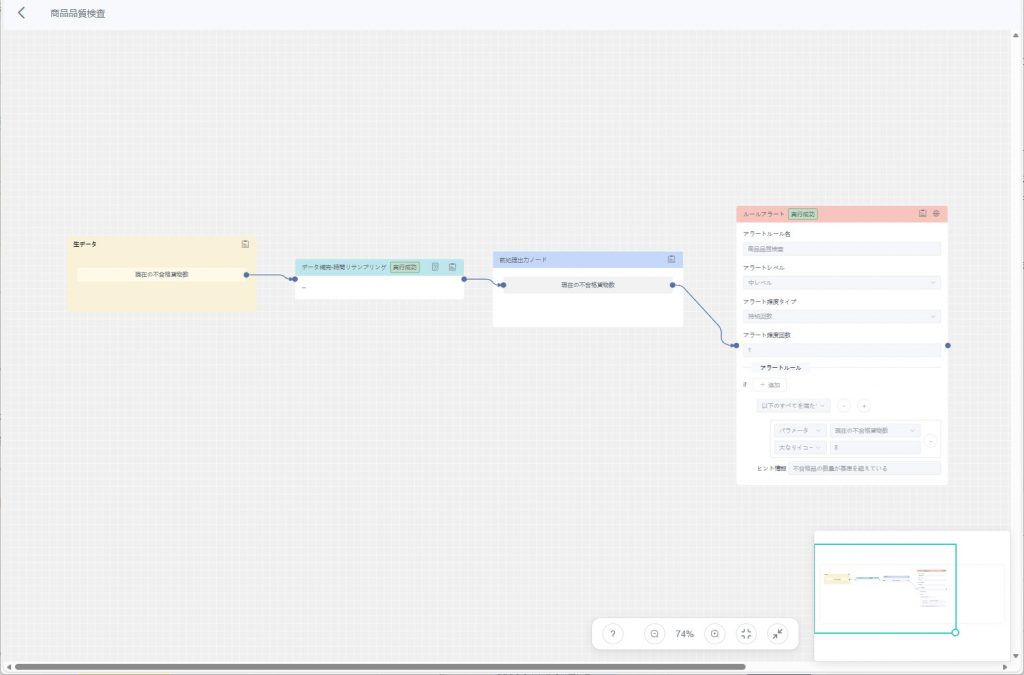
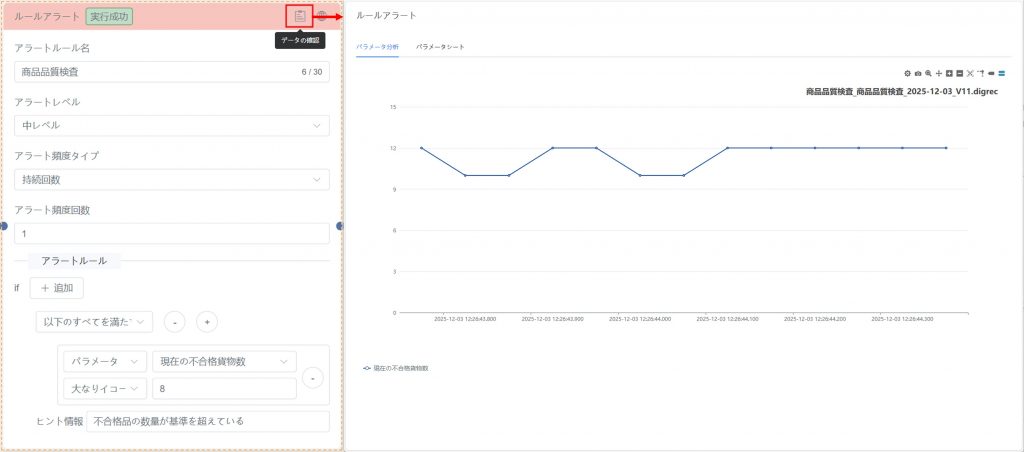
c) キャンバス内で該当するルールアラートノードを選択し、右上の【データ確認】アイコン ![]() をクリックして、グラフ分析画面を開き、異常データの変動傾向を確認します。
をクリックして、グラフ分析画面を開き、異常データの変動傾向を確認します。
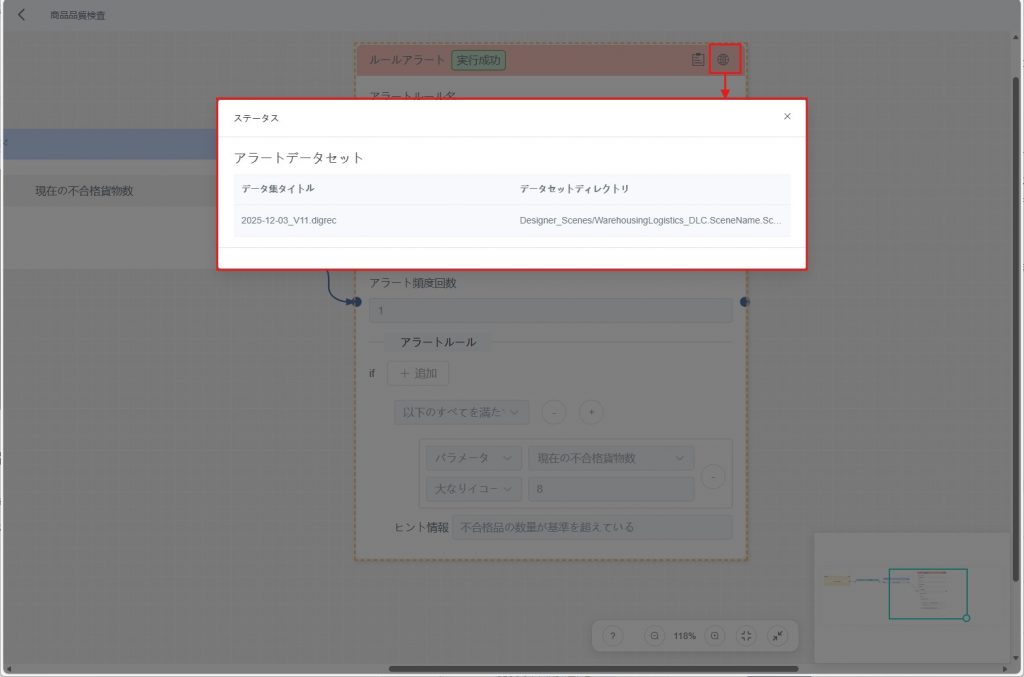
d) 【アラート情報表示】アイコン![]() をクリックすると、当該ルールで使用された元データセットを確認できます。
をクリックすると、当該ルールで使用された元データセットを確認できます。
探索方法管理
本節では、カスタムプリプロセスや特徴量抽出メソッドモデルを用いて、システムのデータ処理能力を柔軟に拡張する方法について詳しく説明します。
事前処理方法管理
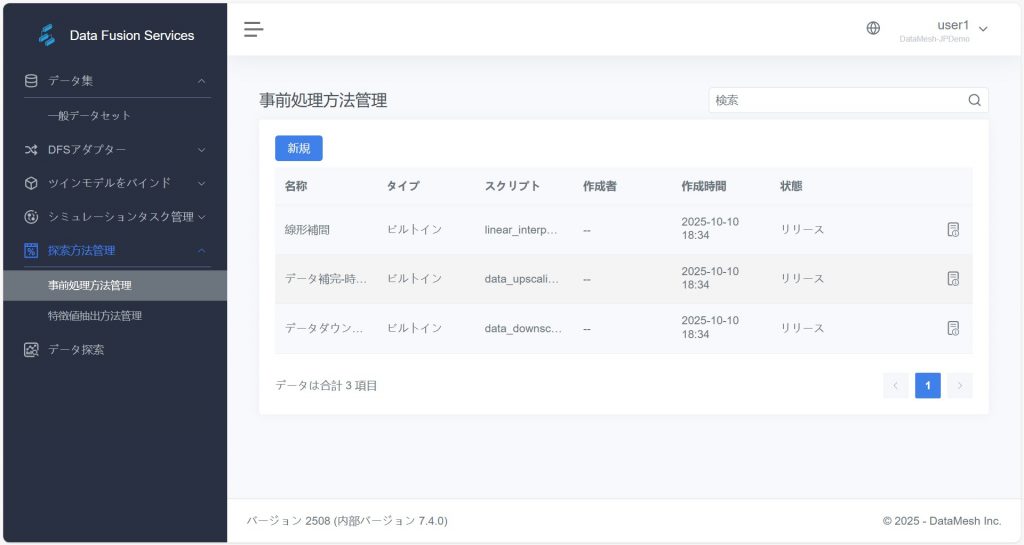
事前処理方法管理ページでは、システム内で利用可能なすべての前処理方法(内蔵方法およびユーザー定義方法)が表示されます。
このページで利用できる機能:
- 事前処理方法の確認:システム内蔵およびカスタムの前処理方法を一覧表示し、名称・説明・スクリプト内容を確認可能。
- 事前処理方法の追加:Python スクリプトをアップロードまたは直接入力することで、新しい前処理方法を追加可能。
- 事前処理方法の削除:不要な方法を削除可能。
内蔵方法
システムには以下の一般的な前処理方法が内蔵されており、ユーザーは直接利用できます:
- 線形補間:データの欠損値を補完、連続データの補間計算に適用。
- データダウンサンプリング:データを降頻処理し、分析要件に合わせてデータ点を削減。
- データ補完 – 時間リサンプリング:時間ベースでデータを再サンプリングし、間隔の不一致を補正。
カスタム方法
ユーザーは Python スクリプトを作成し、独自の前処理方法を定義可能:
- スクリプトファイルのアップロード、またはシステム上で直接入力に対応。
- カスタム方法は複雑なデータシナリオに柔軟に対応でき、拡張性を提供。
カスタム前処理方法
操作手順
- 新規ページに入る:前処理方法管理ページで【新規】ボタンをクリックし、新規作成画面を開く。
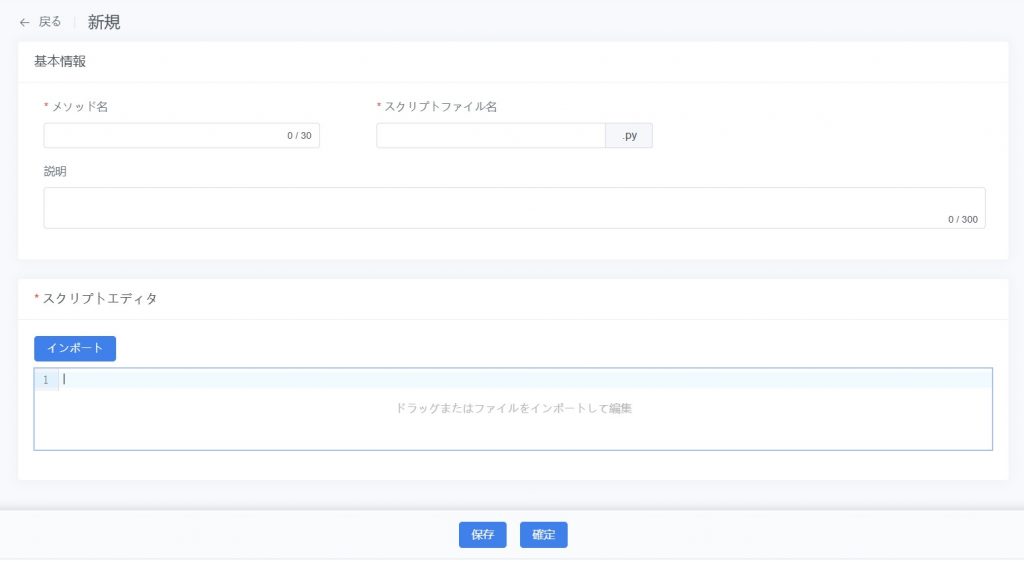
- 方法情報を入力:以下の情報を入力:
- 方法名(必須):方法の名前。
- スクリプトファイル名(必須):前処理に使用するスクリプトファイル名。
- 説明(任意):方法の用途やロジックを補足。
- スクリプトファイルをアップロード:ドラッグ&ドロップまたはファイルインポートでアップロード。
- 方法を保存:【保存】をクリックし、方法を下書き状態で保存。データ探索タスクで有効性を検証可能。
- 公開:検証後、【提出】をクリックして公開状態に更新し、システム内で正式に使用可能。
特徴値抽出方法管理
特徴値抽出方法管理ページでは、ユーザーが特徴量抽出方法を確認およびカスタマイズできます。
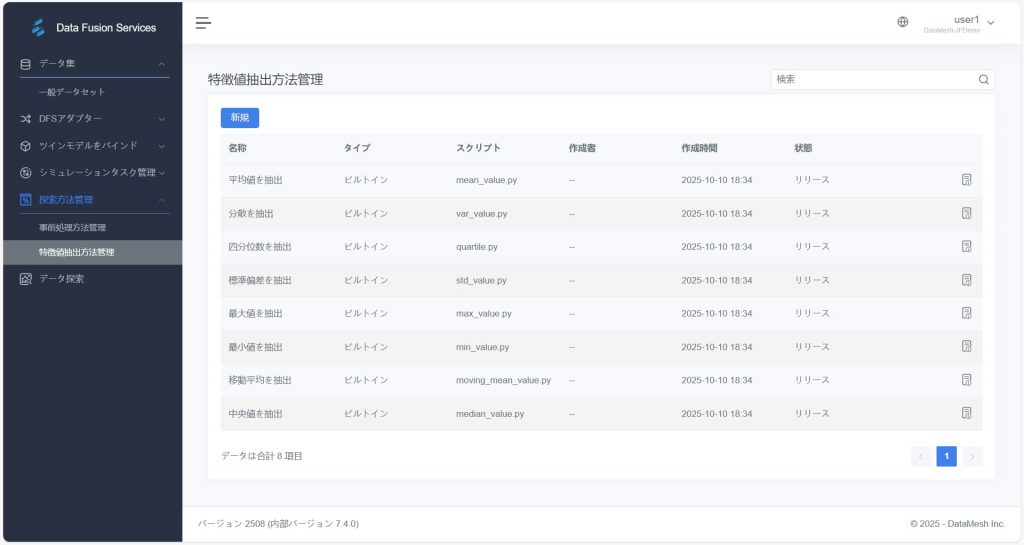
内蔵方法
- 最大値を抽出
- 四分位数を抽出
- 標準偏差を抽出
- 中央値を抽出
- 平均値を抽出
- 分散を抽出
- 最小値を抽出
カスタム方法
- Python スクリプト:ユーザーは Python スクリプトを作成・アップロードすることで、新しい特徴量抽出方法を追加可能。特定の分析要件に対応。
カスタム特徴値抽出方法
操作手順
- 新規ページに入る:特徴値抽出方法管理ページで【新規】ボタンをクリックし、新規作成画面を開く。
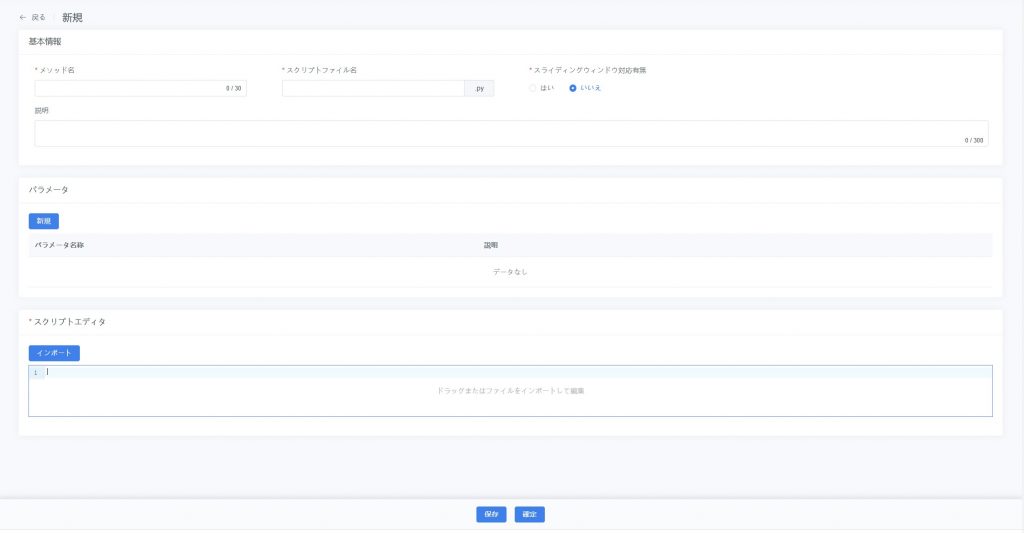
- 方法情報を入力:以下の情報を入力:
- メソッド名(必須):特徴値抽出方法の名前。
- スクリプトファイル名(必須):使用するスクリプトファイル名。
- 説明(任意):方法のロジックを補足。
- スライディングウィンドウ対応有無:[はい]を選択するとスライディングウィンドウ処理を有効化し、ステップ単位でデータを処理し、複数の特徴量を出力可能。
- (任意)動的パラメータの設定:パラメータ欄に調整可能なパラメータを追加し、特徴量抽出の方式を制御。例:「スライディングウィンドウサイズ」パラメータを追加し、探索タスク時に具体値を入力して処理を柔軟に調整可能。
- スクリプトアップロードまたは編集:スクリプトファイルをドラッグ&ドロップ/インポート、または直接 Python コードを入力。
- 方法を保存:【保存】をクリックし、方法を下書き状態で保存。データ探索タスクで検証可能。
- 公開:検証後、【確定】をクリックして公開状態に更新し、タスクで使用可能にする。